
Create a Snowpark Pipeline
Create a Dataflow Using Snowpark Transforms
In this guide, we'll be working to recreate the Snowflake Quickstart Guide. If you haven't done so already, it is recommended to work through the create a Taxi Domain and create a Weather Domain guides for a more general introduction (and to set up an S3 connection).
Step 1: Create the Read Connectors
First, we'll pull in some data to use for our dataflow from an S3 bucket.
Create the CAMPAIGN_SPEND Read Connector
Select Read Connector from the CREATE menu on the tool panel. Select the Sample Datasets connection made in create a Taxi Domain and select USE. On the next screen, hit the Skip and Configure Manually option.
On the Connector Configuration screen, fill the following fields with their respective values:
| Field | Value |
|---|---|
| NAME | CAMPAIGN_SPEND |
| OBJECT PATTERN MATCHING | Match |
| OBJECT PATTERN | snowpark-quickstart-with-ascend/campaign_spend.csv |
| PARSER | CSV |
| FILES HAVE A HEADER ROW | Check this box. |
Once all these fields have been filled, click the Generate Schema button. Once the preview of the records appears, click the Type column value right of the DATE value (the value should be String until a dropdown menu appears, and select Date. The before and after are below:
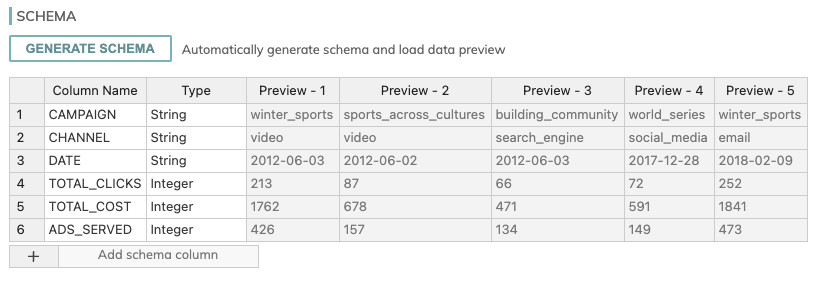
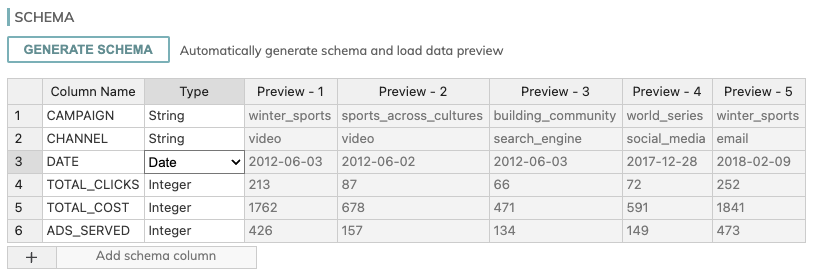
Once the preview of the records appears, you can hit the CREATE button on the top right.
Create the MONTHLY_REVENUE Read Connector
Repeat the steps above for another connector but using the following values instead:
| Field | Value |
|---|---|
| NAME | MONTHLY_REVENUE |
| OBJECT PATTERN MATCHING | Match |
| OBJECT PATTERN | snowpark-quickstart-with-ascend/monthly_revenue.csv |
| PARSER | CSV |
| FILES HAVE A HEADER ROW | Check this box. |
| MODE | PERMISSIVE |
Step 2: Create the Transforms
Next, we'll work with the CAMPAIGN_SPEND and MONTHLY_REVENUE data to create a set of transforms using Snowpark. This set of transformations, which is listed below, will include aggregations and joining two dataframes:
- SPEND_PER_CHANNEL: This transform will group the data from CAMPAIGN_SPEND by the Year, Month, and Channel columns
- SPEND_PER_MONTH: This transform will pivot the information in the Channel column from SPEND_PER_CHANNEL to aggregate the total cost by year and month per individual channel
- REVENUE_PER_MONTH: This transform will group the revenue by the Year and Month columns
- SPEND_AND_REVENUE_PER_MONTH: This transform will join REVENUE_PER_MONTH with SPEND_PER_MONTH
Create the SPEND_PER_CHANNEL Transform
From the CAMPAIGN_SPEND read connector, left-select the vertical ellipsis and select Create new Transform. Name the transform SPEND_PER_CHANNEL and fill in the following fields with their respective pieces of information:
| Field | Value |
|---|---|
| NAME | SPEND_PER_CHANNEL |
| HOW WILL YOU SPECIFY THE TRANSFORM? | Snowpark |
| WHICH UPSTREAM DATASET WILL BE INPUT[0]? | CAMPAIGN_SPEND |
| HOW WILL PARTITIONS BE HANDLED? | Map all Partitions One-to-One |
Once these options are filled out, you should now have an inline code editor available. There, the following code can be input:
from snowflake.snowpark.session import Session
from snowflake.snowpark.dataframe import DataFrame
from snowflake.snowpark import functions as F
from snowflake.snowpark import types as T
from typing import List
def transform(session: Session, inputs: List[DataFrame]) -> DataFrame:
"""Transforms input DataFrame(s) and returns a single DataFrame as a result
# Arguments
session -- A connection with a Snowflake database and provides methods for creating DataFrames
and accessing objects for working with files in stages.
inputs -- A nonempty List of the input components for this Transform. The index of each
input in the list is determined by how the Transform is configured.
# Returns
Any object of type DataFrame
"""
df0 = inputs[0]
df0 = df0.group_by(F.year('DATE'), F.month('DATE'),'CHANNEL').agg(F.sum('TOTAL_COST').as_('TOTAL_COST')).\
with_column_renamed('"YEAR(DATE)"',"YEAR").with_column_renamed('"MONTH(DATE)"',"MONTH")
return df0All other configurations can be left blank.
Now, select CREATE and Ascend will begin processing the Snowpark code above using your connected Snowflake warehouse immediately.
Create the SPEND_PER_MONTH Transform
From the SPEND_PER_CHANNEL transform, left-select the vertical ellipsis and select Create new Transform. As we did above, fill in the following fields and the code editor with their respective pieces of information:
| Field | Value |
|---|---|
| NAME | SPEND_PER_MONTH |
| HOW WILL YOU SPECIFY THE TRANSFORM? | Snowpark |
| WHICH UPSTREAM DATASET WILL BE INPUT[0]? | SPEND_PER_CHANNEL |
| HOW WILL PARTITIONS BE HANDLED? | Map all Partitions One-to-One |
from snowflake.snowpark.session import Session
from snowflake.snowpark.dataframe import DataFrame
from snowflake.snowpark import functions as F
from snowflake.snowpark import types as T
from typing import List
def transform(session: Session, inputs: List[DataFrame]) -> DataFrame:
"""Transforms input DataFrame(s) and returns a single DataFrame as a result
# Arguments
session -- A connection with a Snowflake database and provides methods for creating DataFrames
and accessing objects for working with files in stages.
inputs -- A nonempty List of the input components for this Transform. The index of each
input in the list is determined by how the Transform is configured.
# Returns
Any object of type DataFrame
"""
df0 = inputs[0]
df1 = df0.pivot('CHANNEL',['search_engine','social_media','video','email']).sum('TOTAL_COST').sort('YEAR','MONTH')
df1 = df1.select(
F.col("YEAR"),
F.col("MONTH"),
F.col("'search_engine'").as_("SEARCH_ENGINE"),
F.col("'social_media'").as_("SOCIAL_MEDIA"),
F.col("'video'").as_("VIDEO"),
F.col("'email'").as_("EMAIL")
)
return df1Select CREATE to finish the component.
Create the REVENUE_PER_MONTH Transform
Now, from the MONTHLY_REVENUE read connector, left-select the vertical ellipsis and select Create new Transform. Once again, fill in the following fields and the code editor with their respective pieces of information:
| Field | Value |
|---|---|
| NAME | REVENUE_PER_MONTH |
| HOW WILL YOU SPECIFY THE TRANSFORM? | Snowpark |
| WHICH UPSTREAM DATASET WILL BE INPUT[0] | MONTHLY_REVENUE |
| HOW WILL PARTITIONS BE HANDLED? | Map all Partitions One-to-One |
from snowflake.snowpark.session import Session
from snowflake.snowpark.dataframe import DataFrame
from snowflake.snowpark import functions as F
from snowflake.snowpark import types as T
from typing import List
def transform(session: Session, inputs: List[DataFrame]) -> DataFrame:
"""Transforms input DataFrame(s) and returns a single DataFrame as a result
# Arguments
session -- A connection with a Snowflake database and provides methods for creating DataFrames
and accessing objects for working with files in stages.
inputs -- A nonempty List of the input components for this Transform. The index of each
input in the list is determined by how the Transform is configured.
# Returns
Any object of type DataFrame
"""
df0 = inputs[0]
df0 = df0.group_by('YEAR','MONTH').agg(F.sum('REVENUE')).sort('YEAR','MONTH').with_column_renamed('SUM(REVENUE)','REVENUE')
return df0Complete the component by selecting the CREATE button.
Create the SPEND_AND_REVENUE_PER_MONTH Transform
Now, we'll be creating a transform to join the datasets, which will require this transform to have 2 inputs: SPEND_PER_MONTH and REVENUE_PER_MONTH.
Left-select the vertical ellipsis of REVENUE_PER_MONTH and select Create new Transform. Fill out the fields as usual using the information below. You will have to click the Add Another Input button to select SPEND_PER_MONTH as an input:
| Field | Value |
|---|---|
| NAME | SPEND_AND_REVENUE_PER_MONTH |
| HOW WILL YOU SPECIFY THE TRANSFORM? | Snowpark |
| WHICH UPSTREAM DATASET WILL BE INPUT[0]? | REVENUE_PER_MONTH |
| WHICH UPSTREAM DATASET WILL BE INPUT[1]? | SPEND_PER_MONTH |
| HOW WILL PARTITIONS BE HANDLED? | Map all Partitions One-to-One |
from snowflake.snowpark.session import Session
from snowflake.snowpark.dataframe import DataFrame
from snowflake.snowpark import functions as F
from snowflake.snowpark import types as T
from typing import List
def transform(session: Session, inputs: List[DataFrame]) -> DataFrame:
"""Transforms input DataFrame(s) and returns a single DataFrame as a result
# Arguments
session -- A connection with a Snowflake database and provides methods for creating DataFrames
and accessing objects for working with files in stages.
inputs -- A nonempty List of the input components for this Transform. The index of each
input in the list is determined by how the Transform is configured.
# Returns
Any object of type DataFrame
"""
df0 = inputs[0]
df1 = inputs[1]
df2 = df1.join(df0, ["YEAR","MONTH"])
return df2Congrats, you have created a fully operational Snowpark dataflow in Ascend!
Updated 11 months ago