
AWS S3 Read Connector (Legacy)
Creating an AWS S3 Read Connector
Prerequisites:
- Access credentials
- Data location on AWS S3
- Data Schema (column names and column type)
Specify the S3 path
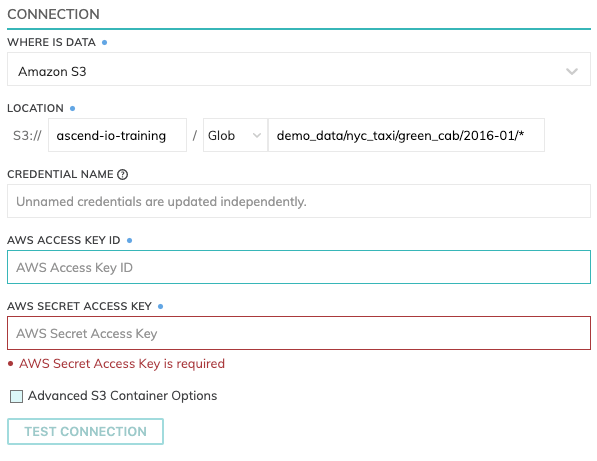
Location
S3 Read Connectors have location settings comprised of:
- Bucket: The bucket name, such as
ascend-io-sample-read-data. - Pattern: The pattern used to identify eligible files:
IAM access
Enter the Access Key and Secret Key for the IAM User. Here's an example S3 policy configuration for this IAM user to create a read connector for data within the bucket s3://ascend-io-playground-bucket/:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:GetBucketPolicy",
"s3:GetBucketAcl",
"s3:GetObject",
"s3:GetObjectAcl"
],
"Resource": [
"arn:aws:s3:::ascend-io-playground-bucket",
"arn:aws:s3:::ascend-io-playground-bucket/*"
]
}
]
}Testing Connection
Use Test Connection to check whether all S3 permissions are correctly configured.
Here is an example:
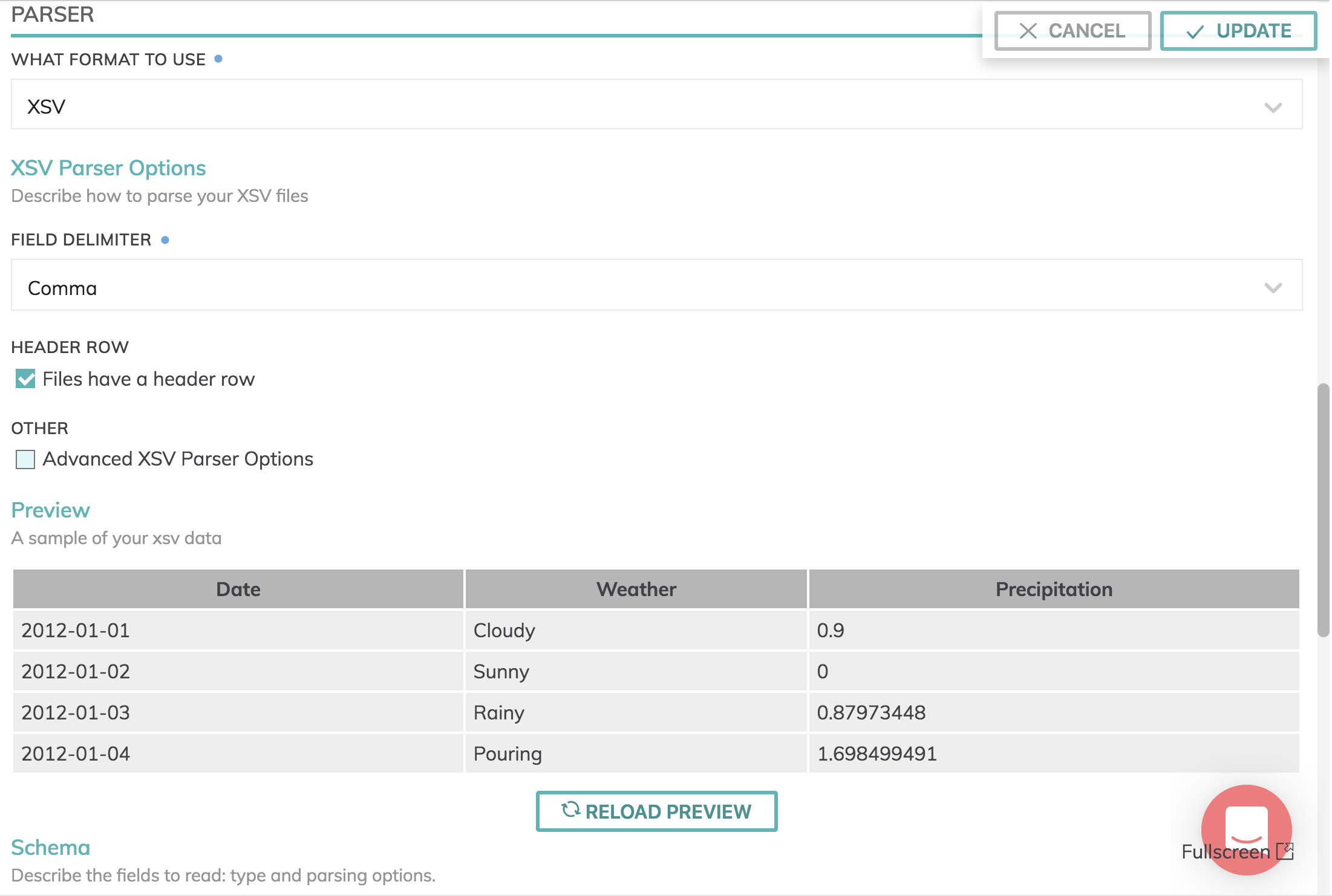
Parsers & Schema
Data formats currently available are: Avro, Grok, JSON, Parquet and XSV. However, you can create your own parser functions or define a UDP (User Defined Parser) to process a file format.
Schema information will automatically be fetched for JSON, Parquet and XSV files with a header row.
Here's an example:
Updated 11 months ago