
Spark Cluster Pools
Manage multi-purpose Spark Cluster Pools, with flexible settings and demand-driven scaling
Overview
Apache Spark is a fundamental part of Ascend, powering various operations including Spark SQL/PySpark transformations, schema inference, data ingestion via Read Connectors, writing data to sinks with Write Connectors, and previewing records from different sources.
Previously, Ascend utilized different backend services for each operation, each launching one or more Spark jobs. Now, all Spark workloads are run on consolidated, multi-purpose Spark clusters, which users can configure. These clusters are grouped into an elastic pool, known as a Spark Cluster Pool. Each Spark Cluster within the pool can run multiple jobs/tasks concurrently.
Configuring Spark Cluster Pools
You have the flexibility to adjust various settings for Spark Cluster Pools. This includes:
- Setting the number of executors
- Adjusting the number of driver and executor CPUs
- Defining the maximum number of clusters in a pool
- Runtime settings: spark version, custom image
For example, a default Cluster Pool might have 16 executors, 5 executor CPUs, 10 driver CPUs, and a maximum of 2 clusters. At peak load, each cluster could utilize up to 6 Standard nodes, meaning the entire Cluster Pool could use up to 12 nodes.
You also have the ability to over-subscribe their cloud compute resources (Node pool) by configuring their Cluster Pools in a way that not all jobs can be scheduled. Over time, Ascend may introduce additional guardrails or warnings to better manage this aspect.
Pre-defined Spark Cluster Pool Sizes
Below is the list of pre-defined Spark Cluster Pool Sizes. Note that not all sizes are available everywhere.
| Size | Driver CPUs | Executor CPUs | Minimum Executors | Maximum Executors | Ephemeral Driver Volume Size | Ephemeral Executor Volume Size |
|---|---|---|---|---|---|---|
| 3XSmall | 3 | 0 | 0 | 0 | 96 | 0 |
| 2XSmall | 7 | 0 | 0 | 0 | 224 | 0 |
| XSmall | 15 | 0 | 0 | 0 | 480 | 0 |
| Small | 3 | 15 | 2 | 2 | 96 | 480 |
| Medium | 7 | 15 | 4 | 4 | 224 | 480 |
| Large | 15 | 15 | 7 | 7 | 480 | 480 |
| XLarge | 15 | 15 | 15 | 15 | 480 | 480 |
| 2XLarge | 15 | 15 | 30 | 30 | 480 | 480 |
| 3XLarge | 30 | 15 | 62 | 62 | 480 | 480 |
| 4XLarge | 60 | 15 | 124 | 124 | 480 | 480 |
Spark Cluster Pool Scaling
Spark Cluster Pools are demand-driven, scaling up or down based on pipeline activity or user activity. A Cluster Pool will scale down if clusters within the pool have been idle for longer than the 'Cluster Terminate After (minutes)' value.
An exception is when the 'Min Clusters in Pool' is set to 1. In this case, there will always be 1 Spark Cluster running in the Cluster Pool, regardless of activity. However, the number of executors in this "always-on" cluster will still scale up and down based on usage.
Assigning Spark Cluster Pools to Data Services
Cluster Pools can be assigned to a Data Service. When assigned, all Spark processing in that Data Service is executed on clusters within that Cluster Pool. If no specific Cluster Pool is assigned, the default Cluster Pool is used.
Default Cluster Pools
The Default Cluster Pool is the default processing cluster pool used by a Data Service and applies to any Dataflow created within that Service. Once a Dataflow is created, you can then change the default cluster pool of that Dataflow within the Data Plane Configuration.
Read Connector Cluster Pools
The spark cluster pool to use for Read Connector activity in a Data Service. This pool will be used for data ingestion workloads.
Interactive Cluster Pools
The spark cluster pool to use for interactive workloads in this Data Service. Interactive work is work Ascend does to process your data such as generating schema and running data quality checks.
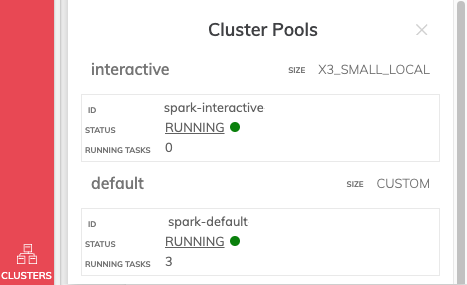
Cluster Pool Status Monitoring
On environments that have the latest version of the Ascend Cluster Manager service enabled, "Clusters" button appears on the left-hand side menu bar, at the bottom of the screen. This handy utility shows you a quick view of the state of the Ascend Clusters associated with the environment, their size, status and number of running tasks.
The Spark Cluster UI for a given cluster can also be accessed by clicking the word "RUNNING" when the cluster is running.
If you don't see this feature, and you are on Gen2 and would like the new Ascend Cluster Manager enabled, please contact Ascend Support.
Updated 11 months ago