
Custom Write with Blob Stores
Custom Write in Ascend allows you full flexibility in how you write your data out to blob store. In this doc, we'll be using the S3 connection as an example, but this method is also available for Azure Data Lake Storage and Google Cloud Storage
Accessing the Custom Write interface
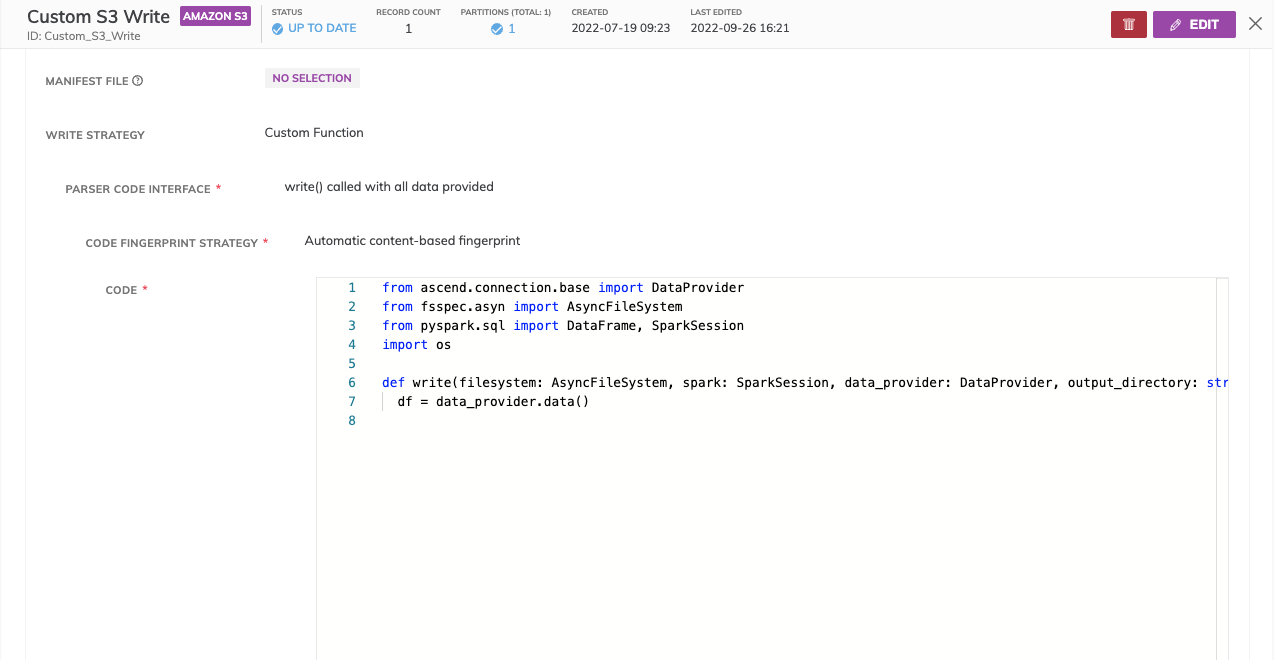
- Create a blob store connection: AWS S3, GCS, ADLS
- Create a write connector: AWS S3, GCS, ADLS
- Set the
Output Directoryfor where the data is written out to. This is a required field and is passed to the write function signature, but can be over-written in code.
Write FormatThe "Format" field for the write connector is still required. However, this does not affect how the Custom Write functions, as you will ultimately program the format in the custom write code.
- Select the following options:
Write Function Signature: Custom Function
Parser Code Interface: write() called with all data provided
Code Fingerprint Strategy: Automatic content-based fingerprint
Using the write() function
def write(filesystem: AsyncFileSystem, spark: SparkSession, data_provider: DataProvider, output_directory: str, **kwargs) -> None:The write() function allows you to specify the logic to write out data to your destination. Below are explanations on the parameters passed in and how to use them:
filesystem: A Pythonic file interface for your blob store (for example, s3fs for Amazon S3) which allows you to carry out standard file-system operations. For example, to open a file for writing in S3, you would write:
with filesystem.open("s3://my-bucket/path/to/file.csv","w"):
f.write(data)spark: the SparkSession, which is the interface for Spark functionality.
data_provider: the Ascend DataProvider class. This provides an interface to access input data. The class definition is as such:
Class: DataProvider
Methods:
partitions(): Returns a Python array of Partition objects (defined below).
schema(): Returns the schema of data as a Spark StructType
data(): Returns all upstream data as a single Spark Dataframe
Class: Partition
Methods:
semantic_sha(): Returns the semantic SHA for the partition. Semantic sha's are determined by
the input data SHA and the SHA of the configuration for the Write Connector
data(): Returns a Spark dataframe for the current partitionoutput_directory: access the Output Directory value from the Write Connector configs.
Example: Writing data partitioned by minute
from ascend.connection.base import DataProvider
from fsspec.asyn import AsyncFileSystem
import pyarrow as pa
import pyarrow.parquet as pq
from pyspark.sql import DataFrame, SparkSession
def write(filesystem: AsyncFileSystem, spark: SparkSession, data_provider: DataProvider, output_directory: str, **kwargs) -> None:
pd = data_provider.data().toPandas()
pd['year'] = pd['at_ts'].dt.year
pd['month'] = pd['at_ts'].dt.month
pd['day'] = pd['at_ts'].dt.day
pd['hour'] = pd['at_ts'].dt.hour
pd['minute'] = pd['at_ts'].dt.minute
pq.write_to_dataset(pa.Table.from_pandas(pd),
filesystem=filesystem,
root_path='s3://ascend-io-sample-data-write/random-words/pyarrow-v3',
basename_template='{i}.parquet',
partition_cols=['year', 'month', 'day', 'hour', 'minute'],
existing_data_behavior='delete_matching'
)In this example, we are writing the data from our upstream component, partitioned by minute, out to S3 using PyArrow. We first create a pandas dataframe by calling toPandas() on the Spark dataframe returned by data_provider.data().
The timestamp we want to partition on is as_ts, so we use Pandas to create year, month, day, hour, and minute columns.
Finally, we use the PyArrow parquet write_to_dataset function to write the data out by passing in our filesystem, specifying the directory we want to write out to, and selecting the columns we want to the data to be partitioned on.
Updated 11 months ago