
AWS S3 Write Connector (Legacy)
Creating an AWS S3 Write Connector
Prerequisites:
- Access credentials
- Data location on AWS S3
- Partition column from upstream, if applicable
Specify the Upstream and S3 path
SuggestionFor optimal performance ensure the upstream transform is partitioned.
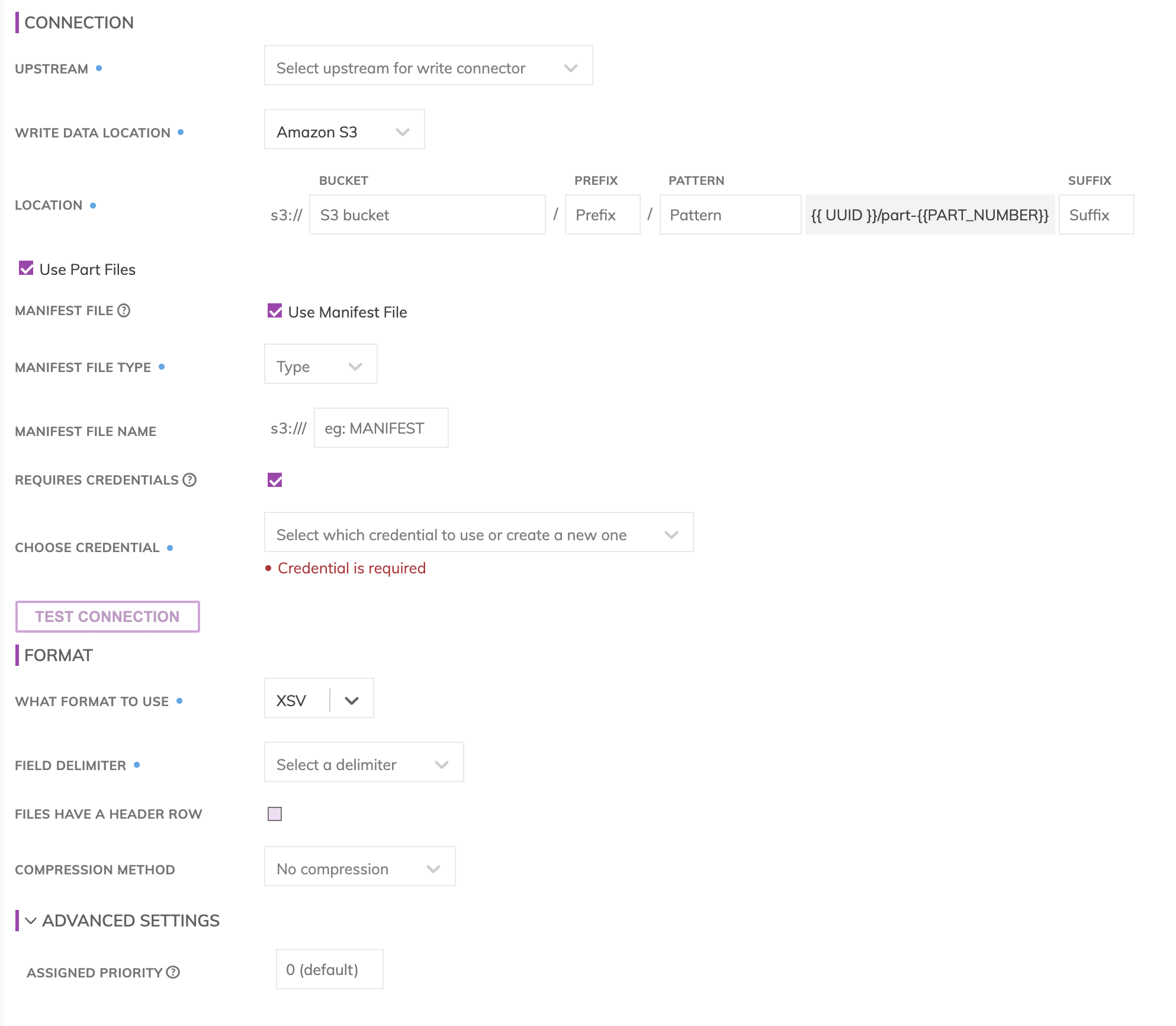
Location
S3 Write Connectors have location settings comprised of:
- Bucket: The S3 bucket name, e.g. my_data_bucket. Do not put in any folder information in this box.
- Object Prefix: The S3 folders hierarchical prefix, e.g. good_data/my_awesome_table. Do not include any leading forward slashes.
- Partition Folder Pattern: The folder pattern that will be generated based on the values from the upstream partition column, e.g. you can use {{at_hour_ts(yyyy-MM-dd/HH)}} where column at_hour_ts is a partition column from the upstream transform.
WarningAny data that is not being propagated by the upstream transform will automatically be deleted under the object prefix.
For example; if the write connector produces three files A, B and C in the object-prefix and there was an existing file called output.txt at the same location Ascend will delete output.txt since Ascend did not generate it.
Manifest file (optional)
If selected a manifest file is generated or updated every time the Write Connector gets Up-To-Date and will contain a list of file names for all data files that are ready to be consumed by downstream applications. To create a Manifest File, specify the full path, including the file name, for where the Manifest File should get created at, as well as whether this should be a CSV or a JSON file.
ImportantMake sure the Manifest File is located under the same folder as the data files.
IAM access
Enter the Access Key and Secret Key for the IAM User which has write access to the path specified. Here's an example policy for writing into the s3 location s3://ascend-io-playground-bucket/write.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:GetBucketPolicy",
"s3:GetBucketAcl",
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:GetObjectAcl"
],
"Resource": [
"arn:aws:s3:::ascend-io-playground-bucket/write/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:GetBucketPolicy",
"s3:GetBucketAcl",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::ascend-io-playground-bucket"
]
}
]
}Testing Connection
Use Test Connection to check whether all S3 permissions are correctly configured.
Selecting a formatter
JSON, Parquet and XSV data formats are supported for S3 and GCS write connectors.
XSV formatter: Supports 3 different delimiters and 9 different line terminators and allows specifying whether a Header Row should be included. The XSV generated is RFC4180 compliant.
ImportantThe XSV Formatter will NOT replace newline characters within values. Replace newline characters in the upstream transform if you require XSV files to contain only single line records.
JSON formatter: Will generate a file where each line in the file is a valid JSON object representing one data row from upstream.
ImportantThe JSON Formatter will automatically replace new line characters in column values to \n in order to guarantee the JSON file has single line records.
Parquet formatter: Will apply snappy compression automatically to the output files automatically.
Updated 11 months ago