
Microsoft SQL Server Write Connector (Legacy)
Creating a Microsoft SQL Server Write Connector
Version Support
The MS SQL Write Connector is compatible with the following MS SQL Server versions:
- Azure SQL Server Managed Instance.
- MS SQL Server Single Instance on Azure.
- MS SQL Server (on-premises) - SQL Server 2017 (14.x) CTP1.1 or later.
Prerequisites:
- MS SQL Server Name
- Port Number
- Database Name
- Table Name
- MS SQL Database Server login credentials (username and password)
- Blob Storage Account Name
- Azure Shared Key for Azure Blob Storage account
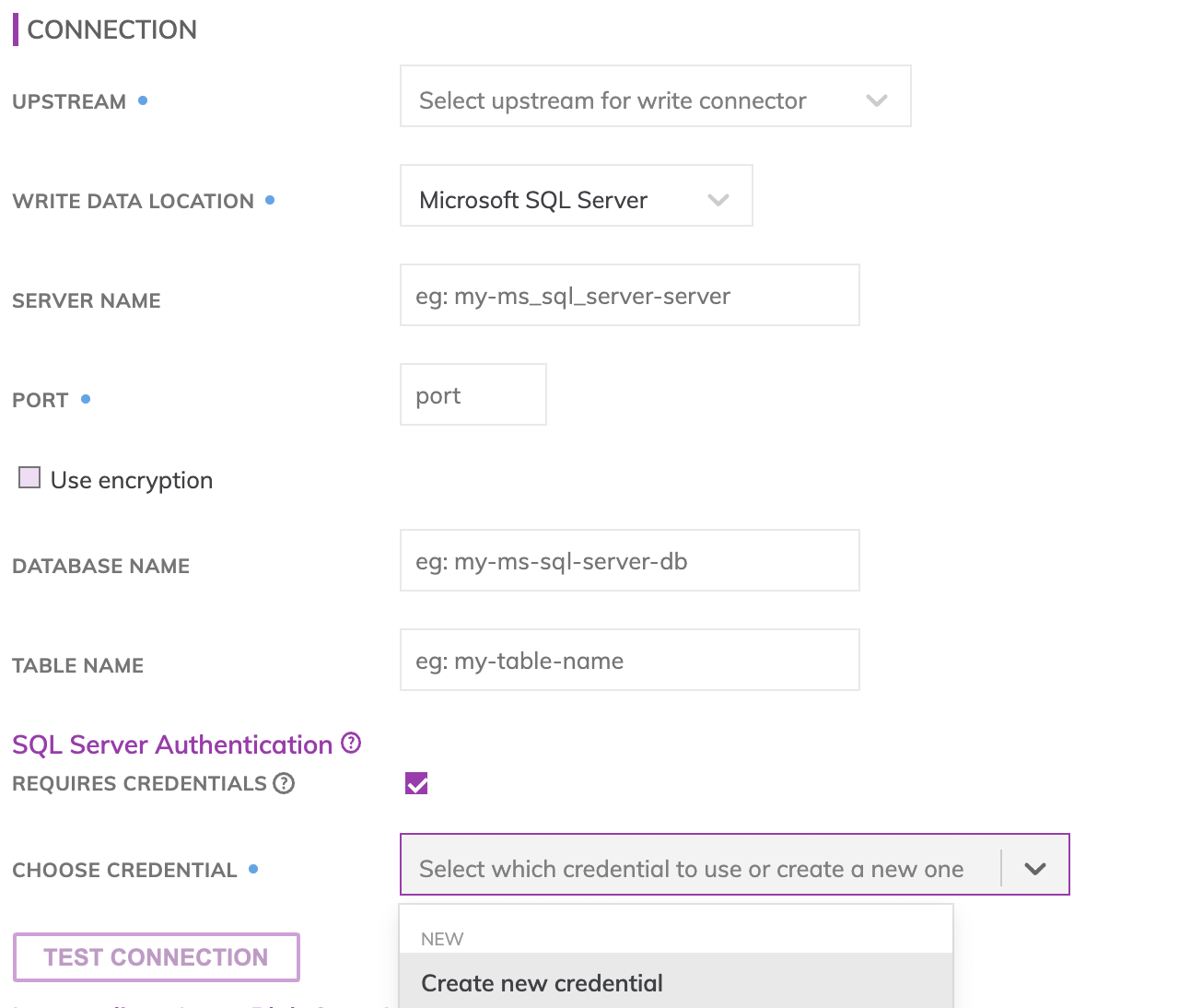
Specify the MS SQL Server Name, Port Number, Database Name, Table Name, and MS SQL Server login credentials information.
SuggestionFor optimal performance ensure the upstream transform is partitioned.
MS SQL Server connection details
Specify the MS SQL Server connection details. These include how to connect to MS SQL Server as well as where data resides within MS SQL Server.
- SQL SERVER NAME: The full name of the MS SQL Server database.
- PORT NUMBER: TCP port 1433 is the default port for SQL Server. This port is also the official Internet Assigned Number Authority (IANA) socket number for SQL Server.
- DATABASE NAME: The name of the MS SQL Server Database to be accessed.
- TABLE NAME: **The name of the MS SQL Server table in which data will get pushed. This table does not need to be created manually before creating the Write Connector. The Write Connector will automatically create this table at runtime.
- CREDENTIALS: The username/password for your MS SQL Server Database.
Testing MS SQL permissions
Use Test Connection to check whether all MS SQL Server credentials are correctly configured.
Azure Blob Storage staging data location
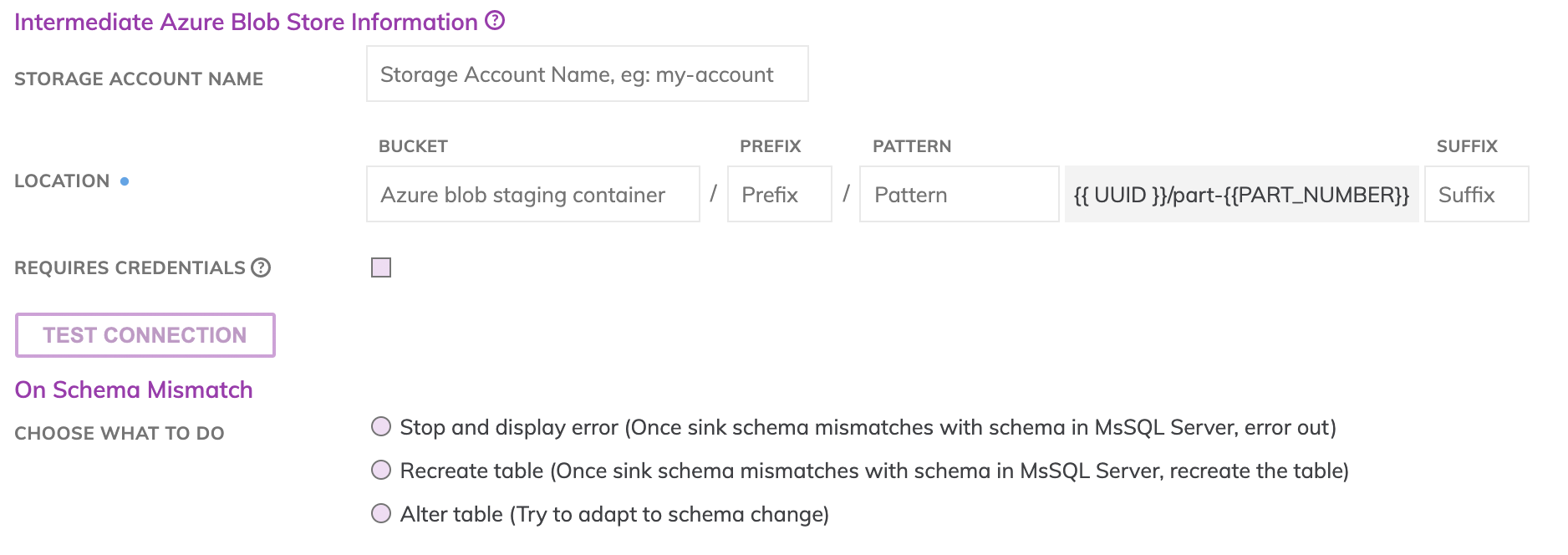
Azure Blob is used as a staging area prior to pushing data into MS SQL Server. This requires configuring an Azure Blob Store with proper credentials. Specify under the Intermediate Azure Blob Store Information section the location where the data files will be created.
- Storage Account Name: The name of the account which has access to this Azure Blob Store.
- Azure Blob Storage Container: The container, e.g. my_data_bucket. Do not put in any folder information in this box.
- Prefix: The Blob Store folders hierarchical prefix, e.g. good_data/my_awesome_table. Do not include any leading forward slashes.
- Partition Folder Pattern: The folder pattern that will be generated based on the values from the upstream partition column, e.g. you can use
{{at_hour_ts(yyyy-MM-dd/HH)}}where column at_hour_ts is a partition column from the upstream transform. - Enter the Azure Shared Key for the Azure Storage Account which has write access to the path specified.
Testing Azure Blob Store permissions
Use Test Connection to check whether all Azure credentials are correctly configured.
WarningAny data that is not being propagated by the upstream transform will automatically be deleted under the object prefix.
For example; if the write connector produces three files A, B and C in the object-prefix and there was an existing file called output.txt at the same location Ascend will delete output.txt since Ascend did not generate it.
Schema Mismatch
You can select from 3 update strategies for scenarios where the schema of the upstream transform changes.
- Stop and display error: Will stop propagating new data to the MS SQL Server table and raise an error in the UI.
- Recreate table: Delete the old MS SQL Server table and create a new table that reflects the new schema. Please note: Any manual changes to the old table outside of the Ascend environment, such as table-specific permissions, will be lost as the newly created table won't mirror the changes from the old table.
- Alter table: Send an alter table command to MS SQL Server in an attempt to update the schema without deleting the original MS SQL Server table such that any changes to the table outside of the Ascend (e.g. user permission, views, etc.) can be preserved. If Alter columns on type mismatch is checked, the alter table command will attempt to change the data type of the column as well. If Drop unknown columns is checked, then any columns added to the table manually outside of the Ascend environment will be removed as a result of the update. The default is both options checked.
Important
- When Alter table option is selected, and the schema of the upstream transform has changed, all rows in the table will be deleted, and new rows will be generated.
- It may not always be possible to alter a table to the desired schema, and If so, an error will be generated to indicate this.
- Additional metadata columns are added automatically to the table schema (prefixed with ASCEND_)
- MS SQL Server sinks directly downstream of sources currently do not work.
- The maximum concurrent writes on 1 table is 20, which is the MS SQL Server default.
- Columns with string fields containing <TAB> characters or line feeds (\n) in the data set are not supported by MS SQL Server. This can be addressed by replacing the tab character in an upstream transform.
- Columns with boolean data are not supported by MS SQL Server. This can be addressed by converting booleans to integers (e.g., IF(<boolean_col>, 1, 0) as
<int_col>).
Updated 11 months ago