
Create a Spark Cluster Pool
Create, update, and delete a Spark Cluster Pool in Ascend.
Requires Site Admin permissions to create. Assigning cluster pools to Data Services and Dataflows requires Data Service and Dataflow Access.
Configure a Cluster Pool
- From the Dashboard, Select Admin > Cluster Pools.
- Select NEW CLUSTER POOL.
- Add a Cluster Pool Name.
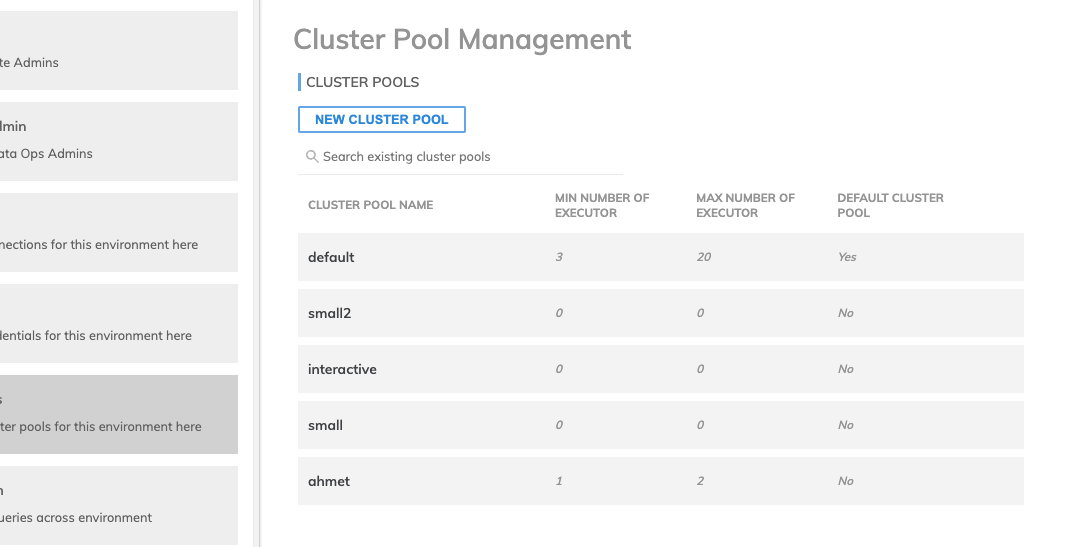
- Update each field to your preferred specifications. Refer to the table below for descriptions of each field.
- Select CREATE.
Cluster Pool Management Properties
| Field | Default | Details |
|---|---|---|
| Min Number of Clusters in Pool | 1 | The minimum number of within the pool. |
| Max Number of Clusters in Pool | 1 | The maximum number of within the pool. |
| Default Cluster Pool | No | The default cluster is labeled as default and cannot be changed from default. Conversely, additional cluster pools cannot be labeled as default. |
| Driver Size in vCPU | 15 | Maximum number is 15. |
| Executor Size in vCPU | 15 | Maximum number is 15. |
| Min Number of Executors | 2 | Default minimum number of executors is 2, default maximum number of executors is 4. For local mode cluster (driver-only), both minimum and maximum number of executors need to be set to 0. |
| Max Number of Executors | 4 | Default minimum number of executors is 2, default maximum number of executors is 4. For local mode cluster (driver-only), both minimum and maximum number of executors need to be set to 0. |
| Cluster Terminates After | 5 | Values in minutes. Default terminate time is 5 minutes |
| PIP Packages to Install for Each Cluster | none | PIP packages are dependencies for Python and with Ascend, you're able to load PIP packages as dependencies/libraries directly into the cluster. However, you cannot install PIP packages that are a different version of packages currently used by Ascend. See the list of pre-installed packages. |
| Ephemeral Volume Size to Mount on Driver | 8 | Volume size in GB. |
| Ephemeral Volume Size to Mount on Executor | 8 | Volume size in GB. |
| Container Image | native | Ascend native container image or "Container image URL" (a custom image) |
| Spark Runtime | Spark 3.4.0 | Spark version of native image or base version of custom image |
Additional fields for custom image option:
Field | Details |
|---|---|
Image Name | Image URL stored in your container registry |
Registry Credentials | Create or select existing credentials that will be used to get access to the image. Credentials should be given in Kubernetes' config.json format. |
Registry credentials format example:
{
"auths": {
"https://gcr.io/<my-company>/": {
"username": "\_json_key",
"password": "{\\n \"type\": \"service_account\",\\n \"project_id\": \"<my-company>\",...}\\n",
"email": "[email protected]",
"auth": "c3R...zE2"
},
"quay.io/<my-company>/": {
"auth": "c3R...zE2"
}
}
}Update a Cluster Pool
When updating cluster pools, any tasks currently using the cluster pool will finish before any updates take effect. You do not need to pause Dataflows before making updates.
- Select the name of the Cluster Pool you want to update.
- Adjust any of the fields.
- Select UPDATE.
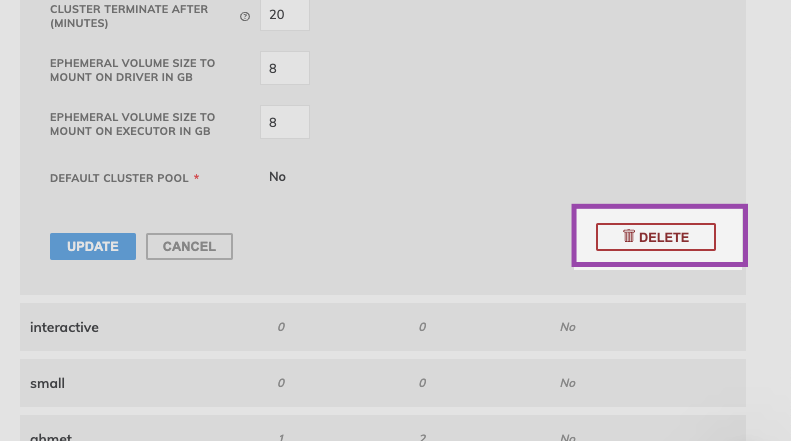
Delete a Cluster Pool
When deleting a cluster pool, any tasks currently using the cluster pool will finish before the deletion takes effect. A cluster referenced in any data service's data plane configuration cannot be deleted. To delete a cluster, first switch it to 'default'.
Alternatively, scale it down to zero by setting 'min_clusters_in_pool' to zero and adjusting 'cluster_terminate_after' to an appropriate value, eliminating the need for deletion.
- To delete a cluster pool, select the name of the cluster pool and then select DELETE.
Updated 11 months ago