
Gen1 Read Connectors
Read from any data source with any format.
Creating a Read Connector
- click BUILD and then select Read Connector to bring up the Connectors panel.

The Connectors panel displays a variety of Read Connectors supported by Ascend.
Select by clicking on the icon for the connector you want to connect to:

Configuring Read Connectors
While there are a variety of connectors, many share similar configuration settings.
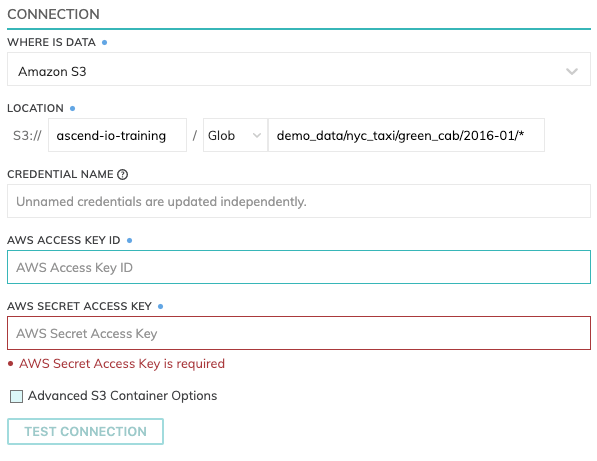
Location
File/Object based Read Connectors such as S3 and GCS have a location setting comprised of
- Bucket: The bucket name, such as
ascend-io-sample-read-data. - Pattern: The pattern used to identify eligible files.
IAM access
Enter the Access Key and Secret Key for the IAM User which has write access to the path specified.
Test Connection
Use Test Connection to check whether all permissions are correctly configured.
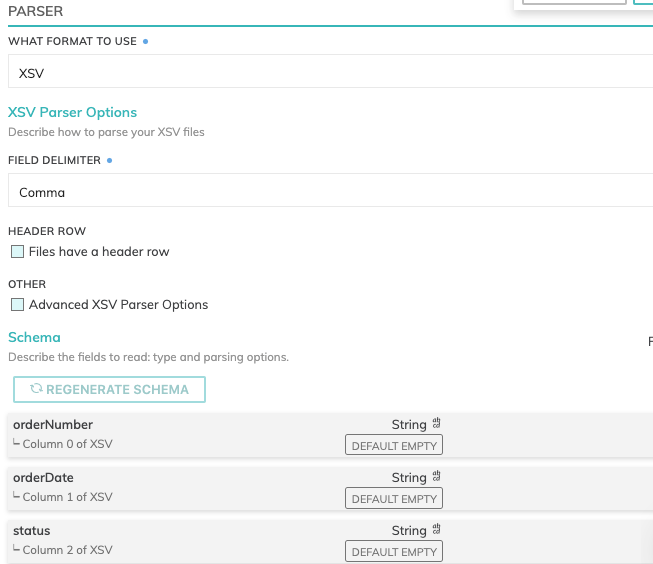
Parsers & Schema
Data formats currently available are: Avro, Grok, JSON, Parquet and XSV. However, you can create your own parser functions or define a UDP (User Defined Parser) to process a file format.
Schema information will automatically be fetched for JSON, Parquet and XSV files with a header row.
Here's an example:
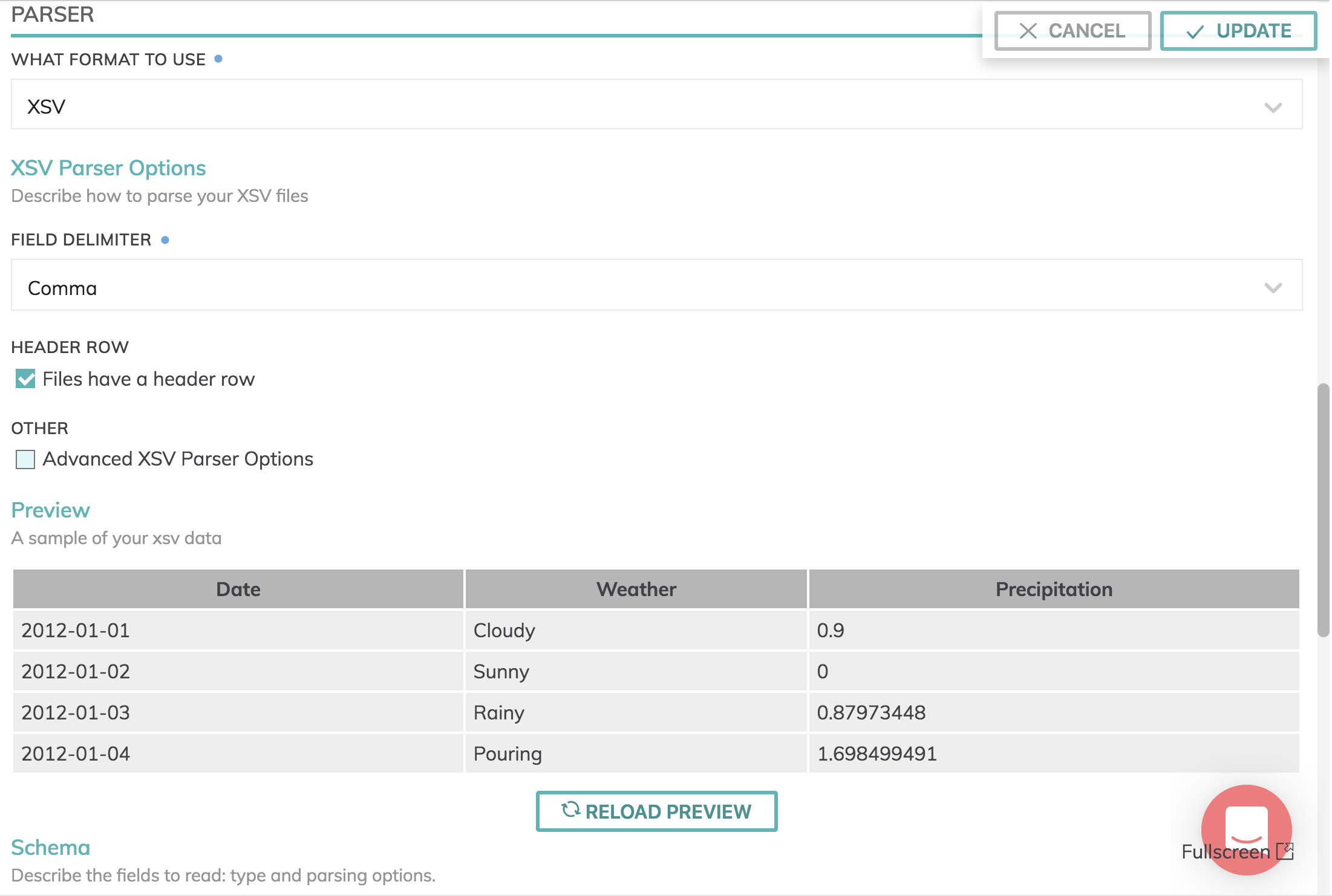
Here is an example of an XSV file:
Connector Refresh Schedule
Choose how often you want to check for new data in the configured source. Never - Manual refresh only; Every N Minutes; Hourly; Every N hours; Daily, Weekly; System Default.
Advanced Section

Processing Priority (optional)
When resources are constrained, Processing Priority will be used to determine which components to schedule first. Higher priority numbers are scheduled before lower ones. Increasing the priority on a component also causes all its upstream components to be prioritized higher. Negative priorities can be used to postpone work until excess capacity becomes available.
Dynamic Source Aggregation (optional)
By default, one partition will be generated per object listed by a Read Connector. If your source directory structure has many small files (which can lead to inefficiencies in big data pipelines), the objects can be aggregated together for parsing, resulting in a smaller final number of partitions. To enable this feature, check the box and choose a maximum size per aggregated object. Aggregation can occur for objects with a common prefix in the same directory (as determined by the delimiter), with a total size under the specified maximum aggregate object size. When aggregation occurs, the reported filename for the aggregated object (and the one accessible to downstream transforms) is the common prefix of the original objects' filenames. Common values for aggregation are between 100 - 1028 MB.
Updated 11 months ago