
PySpark Transforms
Creating PySpark Transforms
PySpark transforms are used for additional control and flexibility in configuring transformations on Ascend.
Add a new transform
Navigate to a Dataflow that already has Read Connector(s) or Data Feed(s). Select Build, Create, scroll down to the Transform section, and click on the PySpark Dataframe API tile.
2020 Ascend Build Transform PySpark Menu
The CREATE NEW TRANSFORM panel appears.
Name the Transform
In the CREATE NEW TRANSFORM panel, enter a name for your Transform under NAME and provide a high-level description of your Transform in the DESCRIPTION text box.
2020 Ascend Build Transform PySpark Name
Specify the Query Type
Choose PySpark in the QUERY section.
For the IS THIS TRANSFORM RECURSIVE checkbox please refer to the Recursive Transforms page in these docs.
Specify the Upstream Datasets
To specify upstream datasets that will be used in PySpark transforms, Ascend provides an array called INPUT[] which is configured with upstream datasets at separate elements. The UI provides the components available in this dataflow.
For example, as shown in the screenshot below, the upstream dataset GreenCab_transform is selected using the dropdown, which defines it as_INPUT[0] for this transform.
Additional upstreams can be added visually using the ADD ANOTHER INPUT button, which defines them as INPUT[1], INPUT[2] and so on.
2020 Ascend Build Transform PySpark Inputs
Specify Partitioning Strategy
This step determines how partitions will be handled. For more details, please refer to the Data Partitioning guide.
2020 Ascend Build Transform PySpark Partition
If you select the Partition by Timestamp option, select the desired column from the upstream dataset to use for partitioning, and granularity as shown below. Note, the column must already be a timestamp type to appear in this dropdown.
2020 Ascend Build Transform PySpark Partition Time Column
Consider the expected amount of data throughput and the potential size and partitions of the partitions when choosing the granularity.
2020 Ascend Build Transform PySpark Partition Time Granularity
Depending on the chosen partition strategy, Ascend will provide a dataframe template to frame the PySpark logic itself.
2020 Ascend Build Transform PySpark Function
Develop PySpark transformation logic
The PySpark transformation development process must follow mandatory steps below:
- Import desired libraries.
- Develop the inbuilt transform function.
- Return a PySpark dataframe as output.
Let's look at each of them in more detail.
Import desired libraries
The sample code provided by default automatically imports just a few libraries from the typing and pyspark.sql modules.
For a detail list of modules that can be imported for use in the Ascend transformation, please refer to the official Apache PySpark documentation.
For example, if you want to develop PySpark transformation logic that uses the window module and other SQL functions, you may want to add import statements like:
from pyspark.sql.window import Window
import pyspark.sql.functions as fn
Develop the transform function
The default transform function can be expanded in two ways:
- Perform complex SQLs with temporary WITH clauses, subqueries, and other nested SQL approaches.
Although these are unavailable with regular Ascend SQL transforms, you can do this by assigning all the upstream datasets to dataframe variables inside the function, creating temporary views using the createTempView function, and then using the sparkSession.sql() method to develop the query you need (screenshot below.)
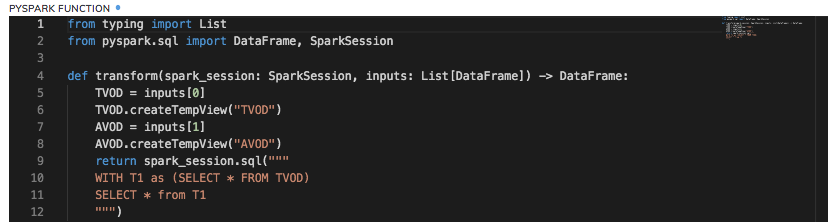
- Perform PySpark Dataframe transformations.
You can develop data transformation logic using the transformations available in the PySpark dataframe API (screenshot below.)
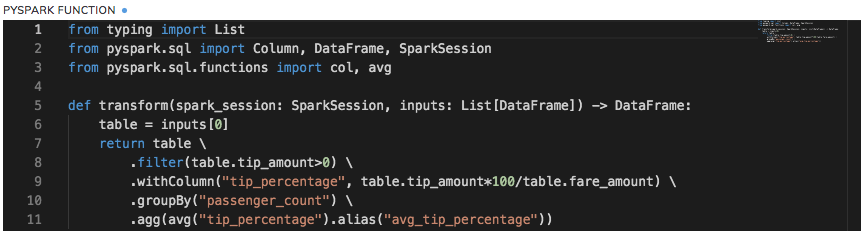
ImportantIn a sequence of PySpark transformations as shown above(filter(), withColumn(), groupBy() etc.), do not use dataframe actions(collect(), count(), first() etc.), unless it is the last step in the sequence of dataframe operations. Dataframe actions interspersed between transformations can cause unpredictable results, and as such are not recommended as best practice by the Apache Spark community.
If you intend to generate an action after a series of transformations and then perform additional transformations based on the results of the earlier action, it is recommended to split this into two Ascend PySpark transformation components right at the place where the action is invoked, instead of doing the entire sequence of operations within a single Ascend PySpark component.
For your reference, a list of valid Spark transformations and actions is maintained at:
https://spark.apache.org/docs/latest/rdd-programming-guide.html#transformations
https://spark.apache.org/docs/latest/rdd-programming-guide.html#actions
Return a PySpark dataframe as output.
Finally, once you've developed the PySpark transformation logic, the last step is to ensure that the return statement in the function returns a PySpark dataframe exclusively. No other data types are supported with the return statement and will error out if attempted. All the sample PySpark transformation screenshots shown in this documentation provide examples of how to return a dataframe.
Advanced Settings
The Ascend platform automatically optimizes a host of parameters that define how jobs are packaged and sent for execution to the Spark engine. The expert data engineer can modify these settings in each transform.
Priority
The ASSIGNED PRIORITY field affects how jobs are sequenced in a resource-constrained environment. This priority applies to all jobs generated by any transform anywhere in the current instance of Ascend.
Credentials
Deselecting REQUIRES CREDENTIALS allows only the buckets that are defined as public to be accessible. Selecting this flag opens a selection to choose from the credentials available in the credential vault.
2020 Ascend Build Transform PySpark Advanced - Credentials
Driver Size
The DRIVER_SIZE field provides for manual override for the size of the driver that is allocated to the execution jobs. Dynamic means that each job is optimized for the amount of data being processed; when this value is fixed, this is no longer optimized.
2020 Ascend Build Transform PySpark Advanced - Driver
Executors
The NUMBER OF EXECUTORS field provides for manual override for the number of executors that are allocated to the execution jobs. Dynamic means that each job is optimized for the amount of data being processed; when this value is fixed, this is no longer optimized.
2020 Ascend Build Transform PySpark Advanced - Executors
Executor Size
The EXECUTOR SIZE field provides for manual override for the size of executors that are allocated to the execution jobs. Dynamic means that each job is optimized for the amount of data being processed; when this value is fixed, this is no longer optimized.
2020 Ascend Build Transform PySpark Advanced - Executor Size
Runtime Engine
The RUNTIME selection allows for matching the PySpark code and required libraries to a specific engine.
2020 Ascend Build Transform PySpark Advanced - Runtime
Finishing up
When all the above steps are completed, click the CREATE button at the top of the panel. This will initiate the processing of the Ascend PySpark transform created.
Pyspark Function Transform Interface
Signature | Required | Purpose |
|---|---|---|
| Yes | Definition of how to transform the input DataFrames into an output DataFrame. Notice the two variations, one if credentials are configured to be included in the component definition, and one without. To infer the output schema of the component, this function will be executed before records are available, replacing the input DataFrame List with DataFrames with schemas matching the inputs, but no records. |
| No | Required Metadata Columns: To request metadata columns for an input, implement this interface. The returned dictionary associates the index of the dataframe inputs to a set of the requested metadata column names. For example, returning |
| No | Schema Inference. Since Ascend needs to know the schema of all transform components, Ascend will by default run the transform function with each input replaced by an empty DataFrame (with matching schema), then inspect the returned DataFrame to determine the component's output schema. By implementing this method to return the output schema, however, Ascend will skip schema inference and use the returned StructType as the output schema. If the transform when run on the data set does not create a DataFrame matching the schema found here, an error will be raised. |
Installing Python modules via pip
The Ascend platform enables you to build your own Spark images, so that you can pip install and then import public or custom Python modules.
There are situations where you may want/need to install additional pip packages in PySpark Transforms for one-time use.
In this case, you may add this script to the top of your PySpark transform code/logic:
import sys
import subprocess
subprocess.check_call([sys.executable, "-m", "pip", "install", "--target", "/tmp/pypkg", "pyarrow"])
sys.path.append("/tmp/pypkg")
# Now you can bring in pyarrow before the transform code
import pyarrow
def transform(spark_session: SparkSession, inputs: List[DataFrame], credentials=None) -> DataFrame:
# do something with pyarrowYou may also specify multiple packages to be installed, in the single subprocess call, by appending more package names at the end of the Python list argument in check_call, as needed.
The specified packages will be automatically downloaded/installed on every instantiation/invocation of your PySpark transform by the Ascend platform.
Updated 11 months ago