
Google BigQuery Read Connector (Legacy)
Creating a Google BigQuery Read Connector
Prerequisites:
- Access credentials
- GCP project name
- BigQuery dataset and table names
- Data Schema (column names and column type)
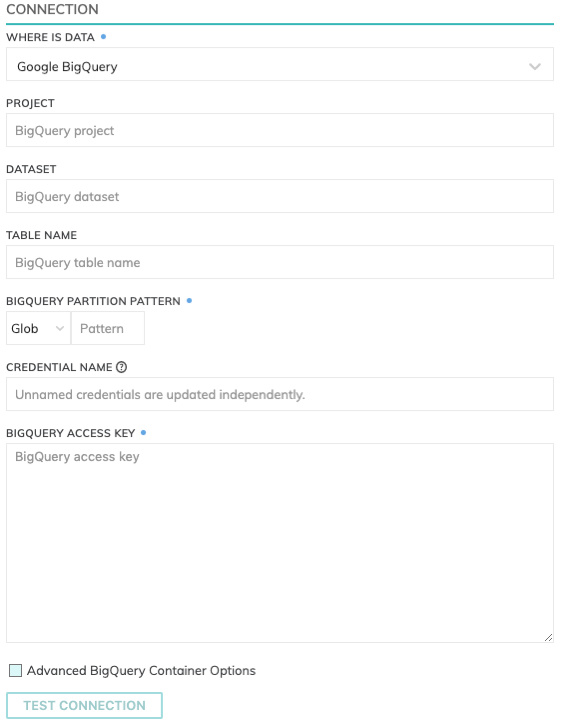
BigQuery Connection Details
Specify the BigQuery connection details. These includes how to connect to Google BigQuery as well as where data resides within BigQuery.
- Project: The Google Cloud Project under which the Table will be created (e.g. my_data_warehouse_project.)
- Dataset: The name of the Dataset where the BigQuery table will be created (e.g. my_very_big_dataset.) Please note: The Dataset needs to be created outside of the Ascend environment and will not be created automatically if the Dataset doesn't already exist.
- Table Name: The name of the BigQuery table. This table does not need to be created manually before creating the Write Connector. The Write Connector will automatically create this table at runtime.
- BigQuery Partition Pattern:
- BigQuery credentials: The JSON key for the service account which has write access to the Dataset specified.
Testing Connection
Use Test Connection to check whether all BQ permissions are correctly configured.
Parsers & Schema
Select BigQuery as the format for parsing the data. The schema will automatically be fetched from BigQuery.
Updated 11 months ago