
Dataflows
Automate data pipelines with Ascend.io's Dataflows through an intuitive Dashboard interface.
A Dataflow is a continuously running data pipeline. You create a Dataflow with a combination of declarative Components to ingest, transform, and output data to an end location. The Dataflow you design is a blueprint that is sent to the Ascend Dataflow Control Plane to be automated.

Creating a Dataflow
- On the Dashboard, navigate to the Data Service where you want to create your Dataflow, and select the New Dataflow button in the top right of the section.
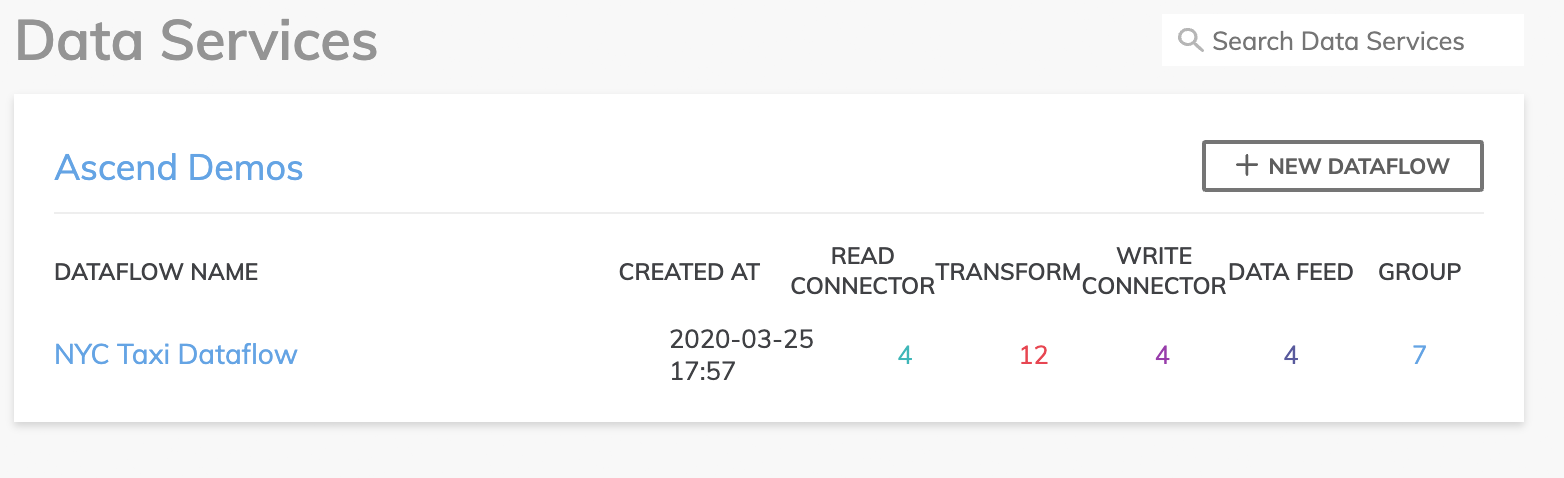
- This will bring up a panel where you give a name to this new Dataflow (required). You can also enter more details to describe your Dataflow (optional).
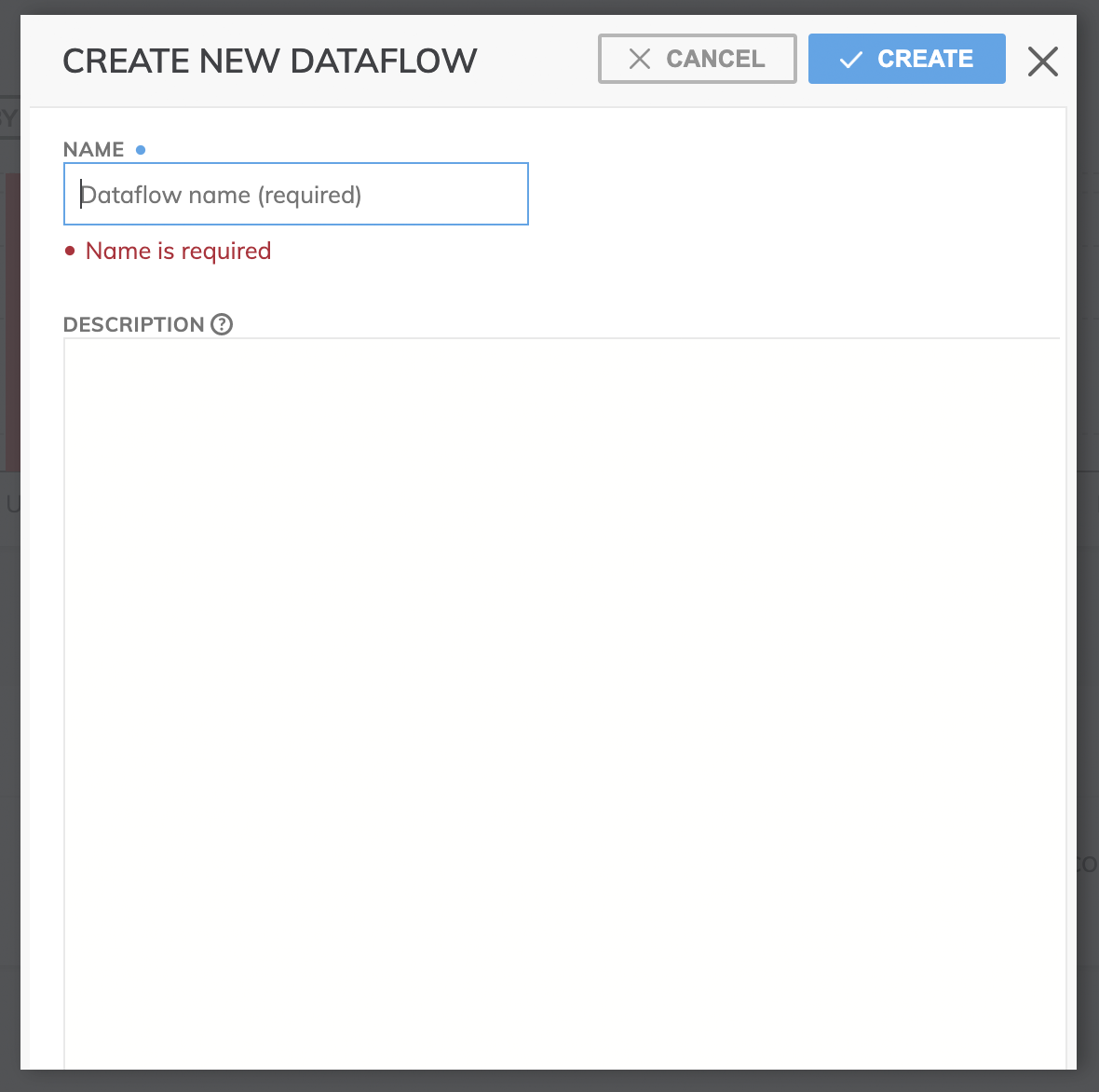
- Click the Create button and a new Dataflow is generated in Ascend!
Advanced Dataflow Topics
Once you've set up your initial Dataflow(s), we suggest coming back here to explore some advanced Dataflow topics, such as:
- Importing & Exporting: Making the most of Ascend's declarative model for rapid branching & merging of Dataflow definitions.
- Workspace: Using the Dataflow Workspace to navigate & explore other components while editing.
- Performance Tuning: Take advantage of Ascend's Profiling & Statistics that analyzes every piece of data, and visualize performance in the Dataflow Timeline.
Updated 11 months ago