
Components
Understand component types and states used in Ascend dataflows
A Component represents an individual data set that maintains its schema, output data set, and statistics about its output data set. Components can be chained together to make an Ascend Dataflows.
Component Types
Below is a breakdown of the different component types available in a Dataflow. All pipelines start with a Read Connector, that can be transformed any number of times and optionally terminate in a Write Connector or a Data Feed.
| Component Type | Description |
|---|---|
| Read Connectors | Read Connectors connect to and synchronize data coming into a Dataflow. Ascend supports many out-of-the-box connectors, as well as a Custom Read Connectors framework for writing your own. |
| Transforms | Transforms manipulate data. They can be written in SQL, PySpark, Scala, or Java. |
| Write Connectors | Write Connectors output data from a Dataflow to an external system and automatically keep the data set synchronized. |
| Data Feeds | Data Feeds connect multiple Dataflows together. They also expose "data as an API" to external systems such as Jupyter, Tableau, and Zeppelin. |
Component Tables for Read Connectors and Transforms
Each Ascend Read Connector or Transform has an underlying component table where we store the data set that is displayed in the records tab of the component. The data store that the component table lives in is determined by the Data Service Type.
Component States
Each component has a state associated with it and these states change as the Dataflow is processed. Below is a breakdown of all the possible states of the component.
| Icon | State Name | Description |
|---|---|---|
 | Up to Date | This component has been computed in its entirety and there is currently no activity upstream which will cause it to change |
 | Running | At least one task is actively computing data |
 | Error | An error occurred while computing data |
 | Pending Analysis | Upstream components are currently processing and this component cannot determine if it needs to process until upstream components finish |
 | Waiting on Upstream | Computation cannot start until upstream components have been computed |
 | Ready to Run | The component is ready to start computation but is either waiting for cluster resources to be available or in a backoff period from a previous error |
 | Blocked by Upstream | An upstream component has an error and this component's computation is blocked until that error is resolved |
| Waiting for Cluster Capacity | The computation can not begin as long as the cluster is busy and can not provide the necessary computational resources to the component |
| Waiting to Update | A data store maintenance operation (typically triggered by a component rename or configuration change) is queued and awaiting execution. |
| Updating Metadata | A data store maintenance operation (typically triggered by a component rename or configuration change) is currently in progress. |
| Waiting to Sweep | The component is done processing and awaiting a final data sweep to remove any outdated data partitions. |
| Sweeping | The component is done processing and currently performing a final data sweep to remove any outdated data partitions. |
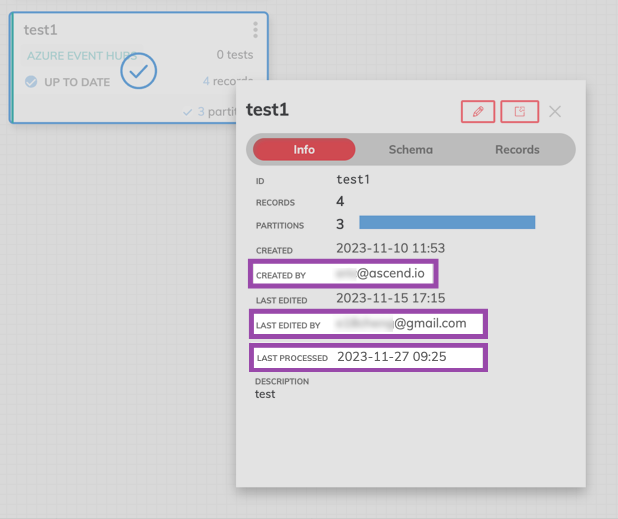
Additional Component Information with the Quick View Panel
Single selecting any Component on the graph will oepn the Quick View Panel of additional information including INFO, SCHEMA, and RECORDS. You can expand any view into fullscreen by using the expand icon.
Within INFO, you can easily view number of records and partitions, created and last edited time stamps, last processed timestamp, and the markdown description of the component. Additionally, the user email of the component creator and see who last edited the component. For Transform Components, you'll also see the SQL query created for that component.
For SCHEMA, the view consists of the Field and Type. If you need to adjust the Type for the field, you'll need to edit the component by selection the red pencil icon.
Note that making changes to schema types will cause the component–and any downstream components in needed–to reprocess.
The RECORDS tab lets you see of all the records for that Component. You can scroll vertically and horizontally to view all details of a record or expand select the expand window icon to open the full window view.
Updated 11 months ago