
System Usage Connection
About the Connection
The System Usage Connection Type enables developers to audit the Jobs, Pods, and Nodes from Ascend.
- Jobs: Represents each individual task that Ascend has scheduled in order to process the Components of a Dataflow. Some jobs, such as cleaning up old artifacts in Blob store aren't associated to a particular Component. Individual partitions and stages of a Component (for example the List Stage of 1 Partition of a Read Connector) are represented as distinct entries.
- Pods: Jobs are executed through different Pods (since Ascend is deployed as a Kubernetes cluster). Pods may be associated to Spark Clusters, the core services of Ascend, operational pods needed for the infrastructure, etc.
- Nodes: The scheduling of Pods drives Kubernetes to scale Nodes, or often referred to as instances as referred to by the cloud providers.
- Billings: Shows hourly recorded job usage on Ascend cluster and data plane (such as snowflake, databricks, or big query)
By creating a System Usage Connection, developers can audit their metadata of Ascend with the same tool chain used for building Dataflows.
Create a System Usage Connection

Figure 1
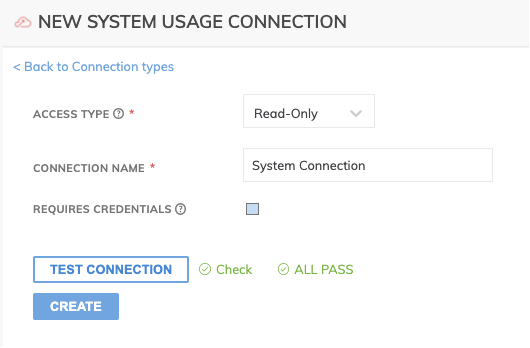
Figure 2
In Figure 2 above:
- Access Type (required): The type of connection: Read-Only.
- Connection Name (required): The name to identify this connection with, such as 'System Usage Connection'.
- Require Credentials (required): The connector does not require any credentials to work
Create New Read Connector
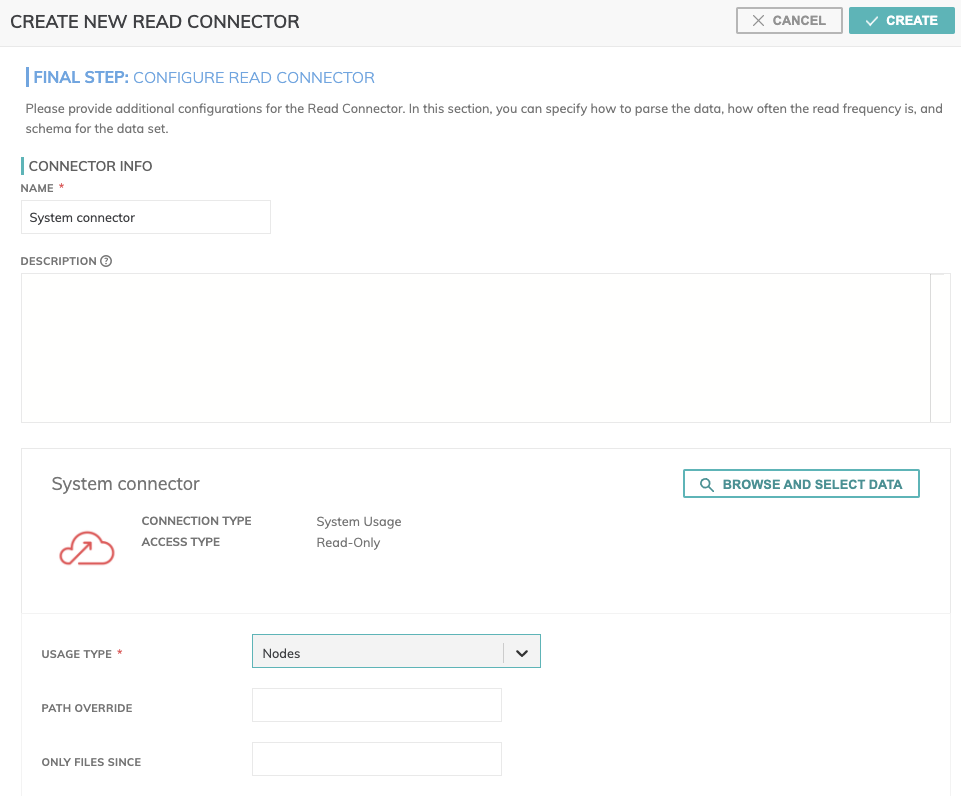
Figure 3
In Figure 3 above:
** CONNECTOR INFO **
- Name (required): The name to identify this connector with.
- Description (optional): Description of what data this connector will read.
Connector Configuration
You can either provide Usage Type(required) from the drop-down menu, which allow you to choose between Pods, Nodes or Jobs or click on Browse and Select Data: this button allows to explore resource and locate assets to ingest.
Jobs
The Jobs data set consists of each individual task that Ascend has scheduled in order to process the Components of a Dataflow.

Figure 4
Data and Fields
Note, fields like data_service_id, dataflow_id, and component_id are only present if the Job is associated to a particular component.
| Field | Type | Data |
|---|---|---|
| scheduled_at | timestamp | When the Job was scheduled by the Ascend scheduler for processing. At this time, the Job and its details are sent to be dispatched to either a running engine to process it or will spin up a new one. |
| finished_at | timestamp | When the Job was complete. |
| data_service_id | string | ID of the Data Service as specified by the Developer. |
| data_service_uuid | string | Ascend internal UUID for the Data Service which persists even if the data_service_id is changed. |
| dataflow_id | string | ID of the Dataflow as specified by the Developer. |
| dataflow_uuid | string | Ascend internal UUID for the Dataflow which persists even if the dataflow_id is changed. |
| component_id | string | ID of the Component as specified by the Developer. |
| component_type | string | The type of the component, such as 'readConnector'. |
| component_uuid | string | Ascend internal UUID for the Component which persists even if the component_id is changed. |
| service | string | What service is used for the component, such as spark, legacy_connector, or internal_system |
| task | string | What processing task this Job was for. |
| cpu_req | double | The CPU cores that were requested for the processing of this Job. For a Spark job, this is calculated as: driver cores + (# of executors * cores per executor). |
| duration_seconds | double | Duration of the Job in fractional seconds, measured as the difference between the scheduled_at and finished_at. |
| status | string | The status of the Job, either 'SUCCESS' or 'FAILURE'. |
| worker_id | string | The ID of the Spark worker node assigned to compute the entry. |
Pods
The Pods dataset contains an entry for every pod on the cluster measured at every minute. This dataset reflects all Pods in the Kubernetes cluster (both for internal Ascend usage and for running customer data processing).
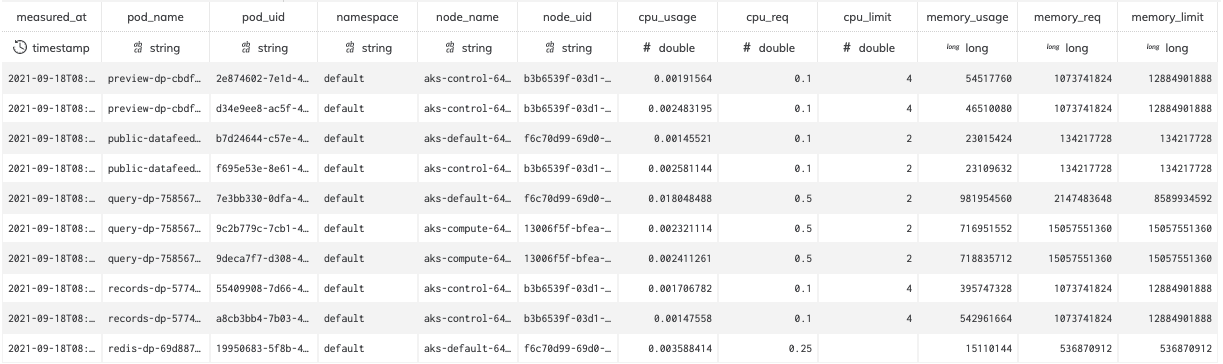
Figure 5
Data and Fields
| Field | Type | Data |
|---|---|---|
| measured_at | timestamp | Timestamp in which Ascend measured the active Pods on the cluster. This interval should be about every minute. |
| pod_name | string | Name of the Pod. |
| pod_uid | string | The Kubernetes Pod identifier, a distinct value for Pods over the lifetime of the Kubernetes cluster. |
| namespace | string | The Kubernetes namespace the pod belongs to. |
| node_name | string | Name of the node where the pod is running. |
| node_uid | string | The Kubernetes Node identifier, a distinct value for Nodes over the lifetime of the Kubernetes cluster. |
| cpu_usage | double | CPU usage for the Pod at the moment of measurement. |
| cpu_req | double | The number of CPU cores requested by the Pod. |
| cpu_limit | double | The upper limit of CPU cores for the Pod. |
| memory_usage | long | The bytes of memory that the Pod is using at the moment of measurement. |
| memory_req | long | The bytes of memory requested by the Pod. |
| memory_limit | long | The upper limit of memory for the Pod. |
| worker_id | string | The ID of the Spark worker node assigned to compute the entry. |
Nodes
The Nodes dataset contains an entry for every node (also referred to as an "instance") on the cluster measured at every minute. This dataset reflects all Nodes in the Kubernetes cluster (both for internal Ascend usage and for running customer data processing).
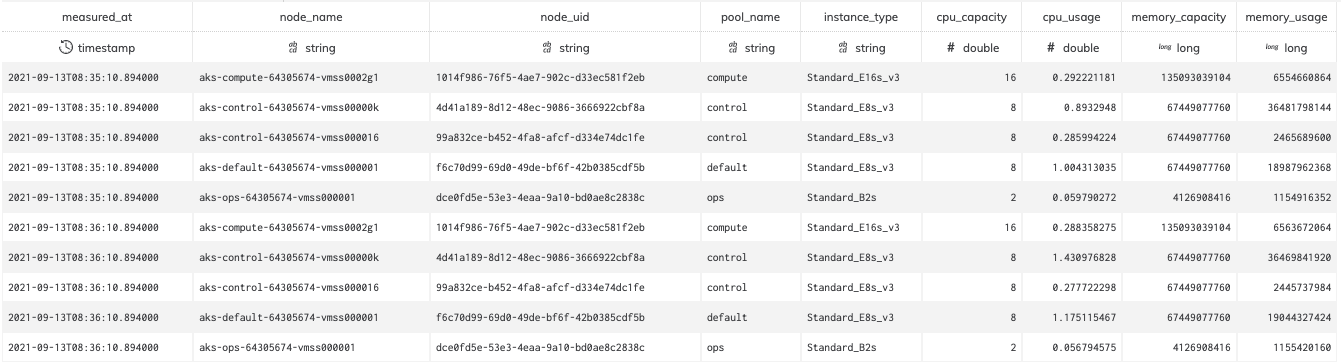
Figure 6
Data and Fields
| Field | Type | Data |
|---|---|---|
| measured_at | timestamp | Timestamp in which Ascend measured the active Pods on the cluster. This interval should be about every minute. |
| node_name | string | Name of the Node. |
| node_uid | string | The Kubernetes Node identifier, a distinct value for Nodes over the lifetime of the Kubernetes cluster. |
| pool_name | string | Name of the Kubernetes pool that the node belongs to. Values include compute and default. The compute pool is likely of most interest as these nodes are used for data processing. |
| instance_type | string | The virtual machine type used from the underlying Cloud Provider. |
| cpu_capacity | double | The number of CPU cores the Node has. |
| cpu_usage | double | CPU usage for the Node at the moment of measurement. |
| memory_capacity | long | The bytes of memory the Node has. |
| memory_usage | long | The bytes of memory that the Node is using at the moment of measurement. |
Billings
The Billings dataset contains an entry for billable usage on the cluster measured at every hour. This dataset reflects the vcpu usage per hour or credits in the Kubernetes cluster (both for internal Ascend usage and for running customer data processing) and in the dataplane.
Data and Fields
| Field | Type | Data |
|---|---|---|
| at_hour | timestamp | Timestamp in which Ascend measured the billing usage. This interval should be about every hour. |
| data_plane_type | string | The type of data plane. |
| data_plane_id | string | The id of data plane |
| data_plane_name | string | The name of data plane. |
| dfcs | double | |
| vcpu_hrs_cluster | double | |
| snowflake_credits | double | |
| databricks_dbus | double | |
| bigquery_tbs | double |
Updated 11 months ago