
Read Connector
After creating an Amazon S3 connection, set up a Read Connector in your dataflow.
Create a new Read Connector
To get started, select Read Connector from the Ingest tab.

FIgure 1.
Step 1: Select your connection.
Find your newly created connection and select USE.

Figure 2.
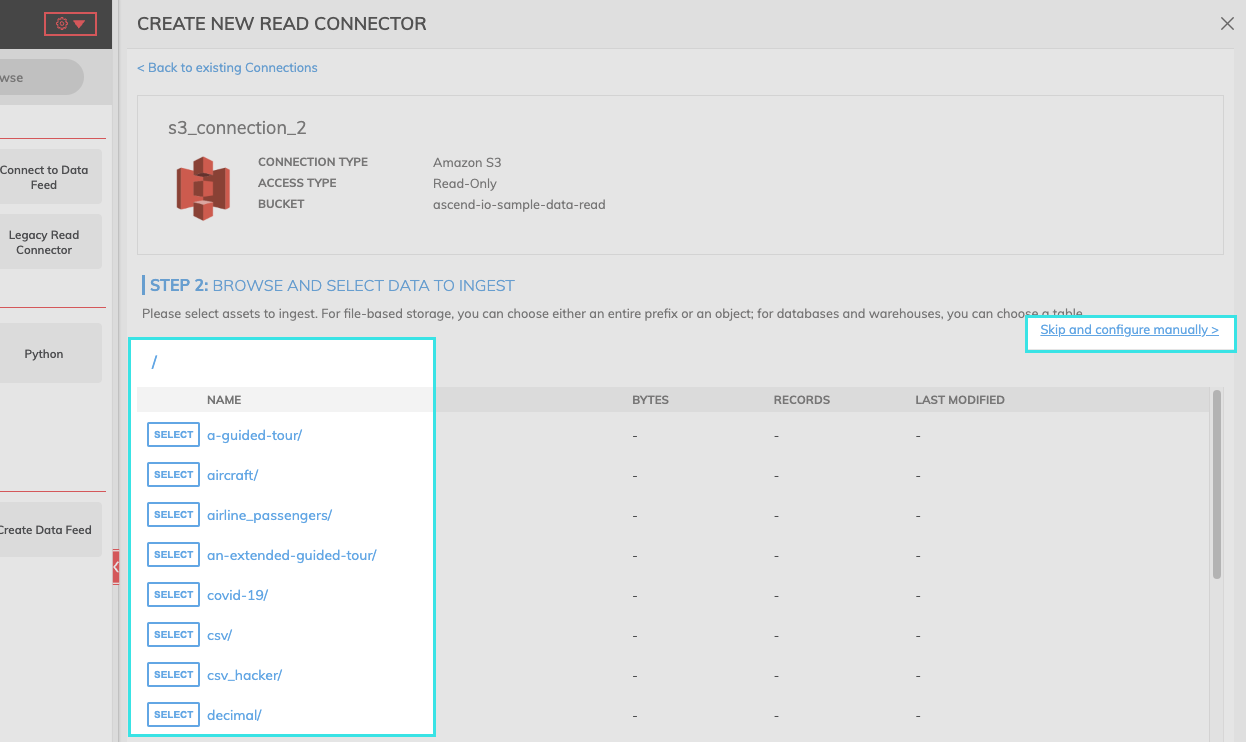
Step 2: Select the data to ingest.
If you know the path of the data you want to ingest, select "SKIP and configure manually."
Step 3: Provide the required Connector information.
Field | Required | Description |
|---|---|---|
BUCKET | Required | Name of the S3 bucket. |
OBJECT PATTERN MATCHING | Required | The pattern strategy used to identify eligible files: |
OBJECT PATTERN | Required | The specific pattern parameters used to identify eligible files. Example: find all the files with Prefix Flights_. |
PARSER | Required | We support several data formats. See Amazon S3 Read Connector Parsers](https://developer.ascend.io/docs/amazon-s3-read-parser) for more information about CSV, Excel, JSON, and Python parsers: |
PATH DELIMITER | Optional | Example: A newline(\n) de-limited file |
OBJECT AGGREGATION STRATEGY | Required | Currently available strategies are:
|
Schema
Once you click on the GENERATE SCHEMA button, the parser will create a schema and a data preview will be populated as in the Figure 5 below.
Add Custom Schema: After schema is generated, you can add custom columns. To insert a column, select Add schema column. To edit the custom schema, right click anywhere in the row and select either Insert row above, Insert Row below, or Remove row.

Figure 3.
Refresh Schedule
The refresh schedule specifies how often Ascend checks the data location to see if there's new data. Ascend will automatically kick off the corresponding read jobs once new or updated data is discovered.
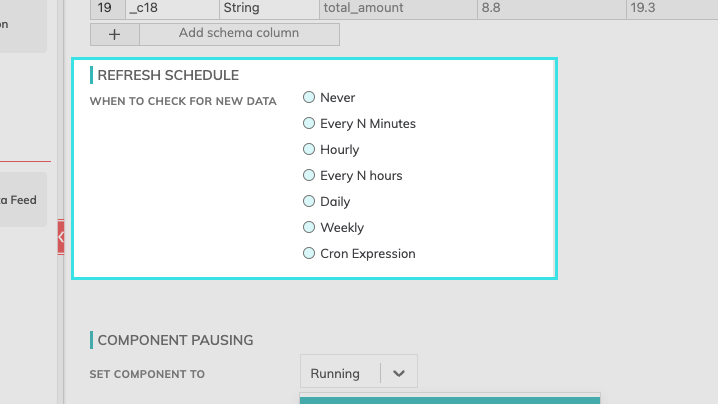
Component Pausing
Update the status of the read connector by selecting either Running to mark it active or Paused to stop the connector from running.

Figure 4.
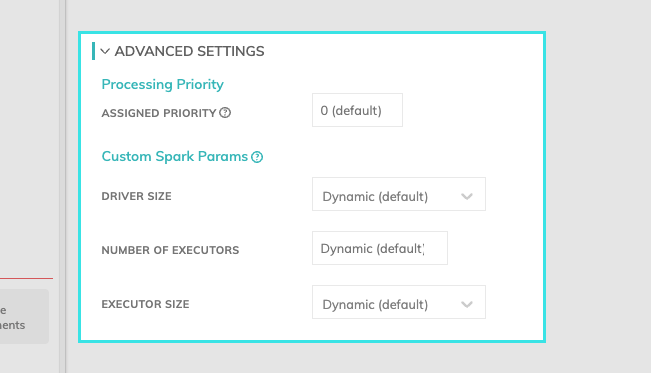
Advanced Settings
Processing Priority: When resources are constrained, this value will be used to determine which components to schedule first. Higher priority numbers are scheduled before lower ones. Increasing the priority on a component also causes all its upstream components to be prioritized higher. Negative priorities can be used to postpone work until excess capacity becomes available. Please note that once a job is running, it completes processing and isn't impacted by a higher priority item coming into the queue.
Custom Spark Params: You can determine the resources such as driver size, number of executors, and the executor size. If you leave this set to Dynamic (default), Ascend will inspect the input files and automatically estimate the appropriate cluster size.
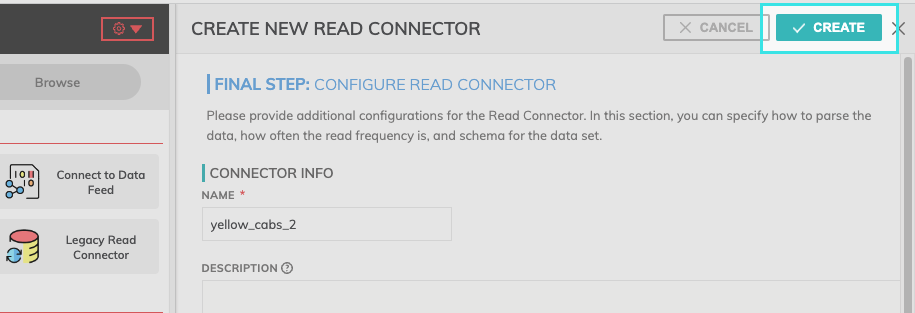
Final Step: Select create.
After providing the required Connector information and adjusting any additional settings, select create from the top right-hand corner.
Updated 11 months ago