
Custom Python
Creating a Custom Python Read Connector
Looking for the Legacy Custom Python Read Connector?Ascend is in the middle of updating these docs to reflect our new custom Python Read Connectors which have been recently released.
If you are looking for the Legacy Custom Python Read Connector interface, from the Build -> Ingest menu, please choose "Legacy Read Connector" - and then for "Read Data Location" choose "Custom" to access the old legacy user interface/experience.
Prerequisites
- Python code that can read in data and produce rows and columns
- Access credentials
- Data schema for the dataset
- Business logic on how incremental data should be processed
Create a connector
From the Build Menu, in Create mode, under the READ section, choose "Custom Python" to create a custom Python read connector.

Image 1.
Custom code
Ascend requires you to implement 3 python functions in your custom read connector:
- context: Creates the session that your code will work within.
- list_objects: Creates a list of all data fragments identified by the fingerprint value.
- read_bytes: Generates the rows and columns for 1 individual data fragment.
context functionWe recommend completing the session setup here, e.g. create the database connection, the HTTP session, etc. User input credentials are only available through this function.
# context function creates the session for rest of the code to work with. credentials will be the string representation of the credentials you select for this connector.
def context(credentials: str):
try:
ctx = json.loads(credentials)
return ctx
except Exception as e:
print(e)
return {}
list_objects functionAscend runs the list_objects function every time the read connector refreshes and only processes data fragments that either:
- Have a name that does not already exist in the previous refresh,
Or- Have a name that exists in the previous refresh but has a fingerprint.
# list_objects function creates a list of all data fragments identified by the fingerprint value
'''
schema for list objects
{
'name': <object name >,
'fingerprint': <unique string to indicate if an object has been modified since last read',
'is_prefix': <used for blob storage case, it is indicate prefix to stop searching>
}
'''
from google.protobuf.timestamp_pb2 import Timestamp
def list_objects(context: dict, metadata: dict):
if metadata:
obj = {'name': 'fragment1', 'fingerprint': 'md51', 'is_prefix': False}
yield obj
obj = {'name': 'fragment2', 'fingerprint': 'md52', 'is_prefix': False}
yield obj
else:
obj = {'name': 'folder1', 'fingerprint': 'fmd51', 'is_prefix': True}
yield obj
read_bytes function
- The read_bytes function will run once for every data fragment that needs to be processed from the list_objects function (e.g. read_bytes will run 10 times if the list_objects yielded 10 data fragments.)
- The read_bytes function will not be run multiple times for the same fragment. Additionally, if read_bytes throws an uncaught exception, the entire read connector will error out.
- It's acceptable to yield data points in a format other than CSV, as long as the Parser is configured properly.
# read_bytes function generates the rows and columns for 1 individual data fragment
def read_bytes(context: dict, metadata: dict):
yield ",".join(metadata['name'], metadata['fingerprint'])Below is a screenshot implementing these Python functions as code in the Ascend editor.

Image 2. Screenshot of Ascend code editor.
Install pip packages
Ascend also supports installing of any pip packages via the PIP PACKAGES TO INSTALL area as shown below. You can add custom pip packages that your Python code will require by typing the name of the package and pressing the "enter" key. These packages will be installed automatically by the Ascend platform before running the custom code.
Please contact Ascend at [email protected] if you want to connect to private packages and libraries.

Need Specific pip Package Versions?If you need to install specific pip package versions through the UI, you may enter them in standard pip versioned package format, such as package==X.Y.Z. Any versions of the package that you install here will take precedence over the default packages in the Ascend Docker image.
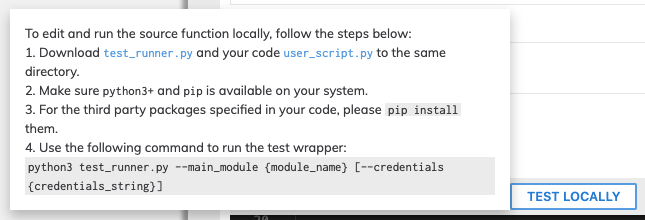
Test Locally
The ability to test the code locally can be extremely helpful and expedite the connector development process. Please follow the instructions to download the wrapper in order to test the code locally.
Parsers & Schema
Data formats currently available are: Avro, JSON, Parquet and XSV. However, you can create your own parser functions to process a file format.
For custom read connectors, you will need to create the schema with column names and data types as well as specifying default values etc.
# Custom parser function example:
import json
def parser_function(reader, onNext):
# Use reader to read in data, and pass a python map to onNext function as parsing result.
# Reader is a python non seekable file like object
# onNext is a callback function expecting a dict object for each row value.
for line in reader:
# strip spaces and skip on empty line
line = line.strip()
if line:
# "loads" will convert line to python map
onNext(json.loads('{ "col1":"' + line + '" }'))
reader.close()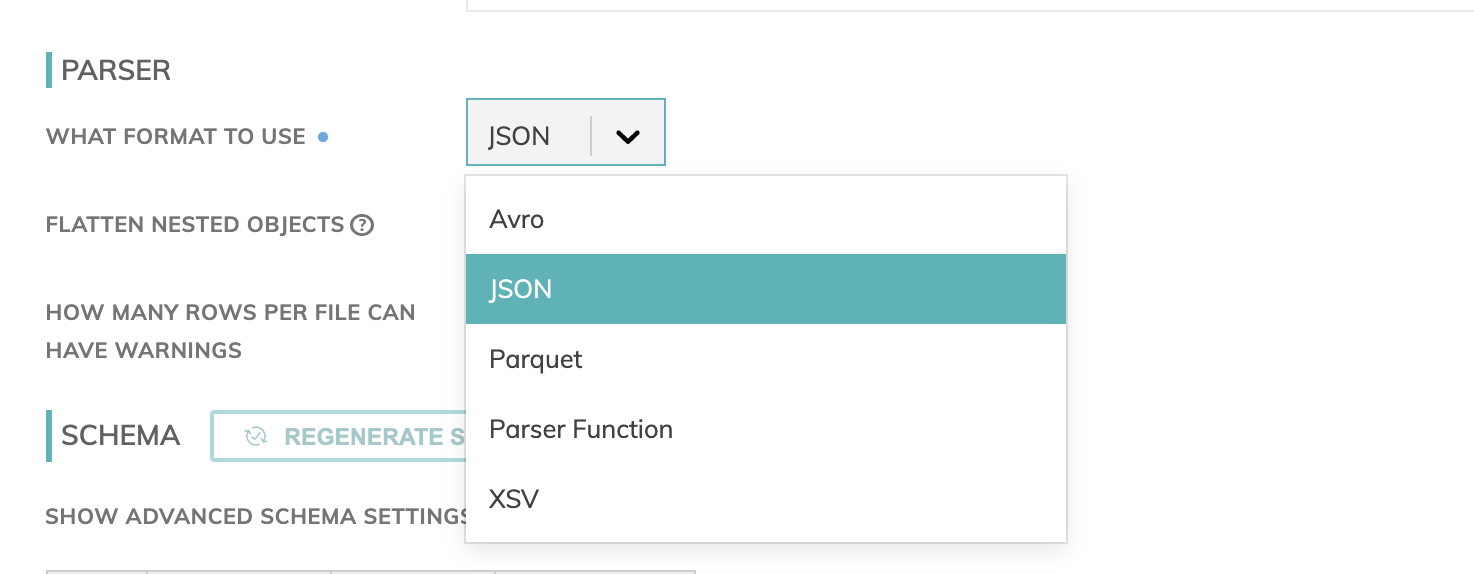
Updated 11 months ago